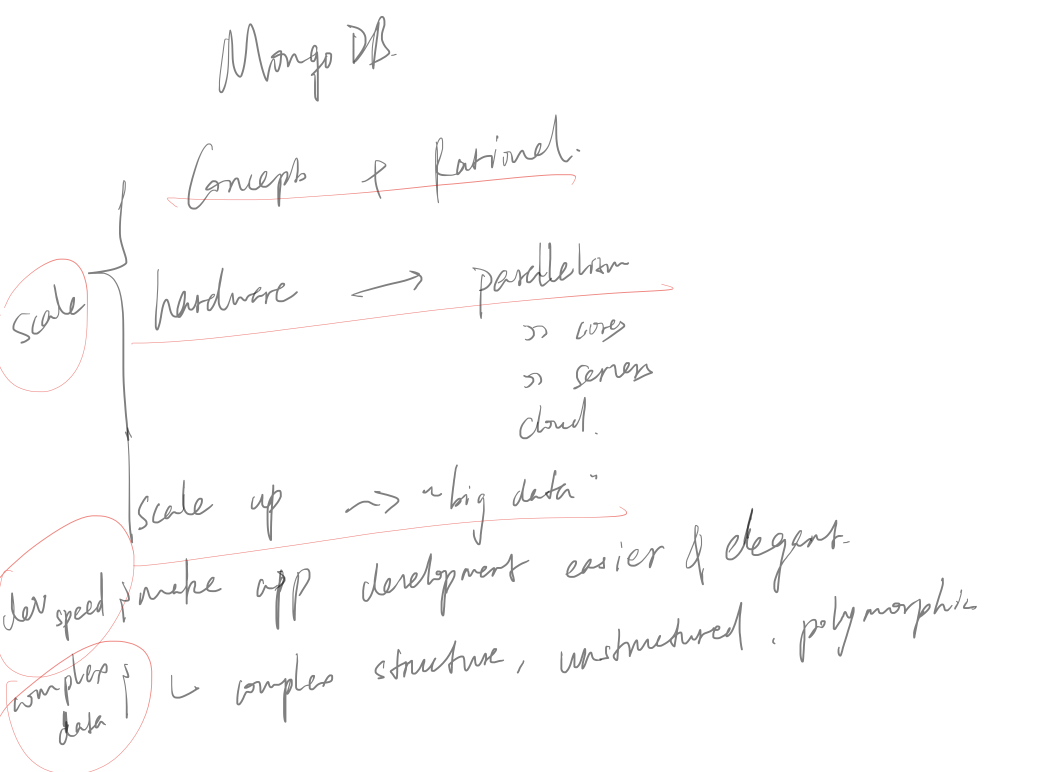
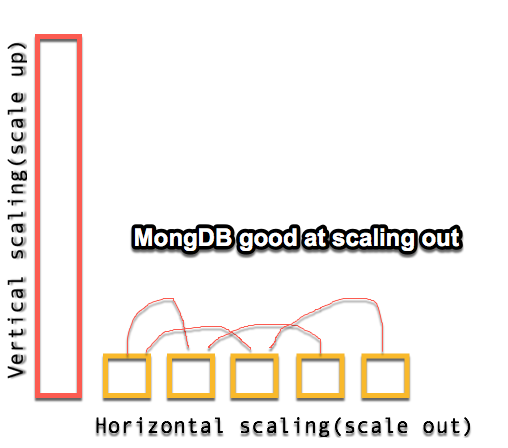
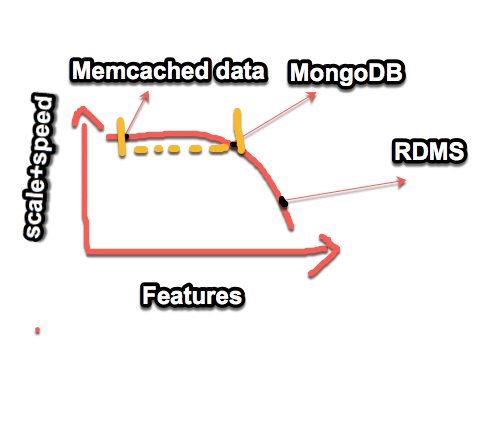
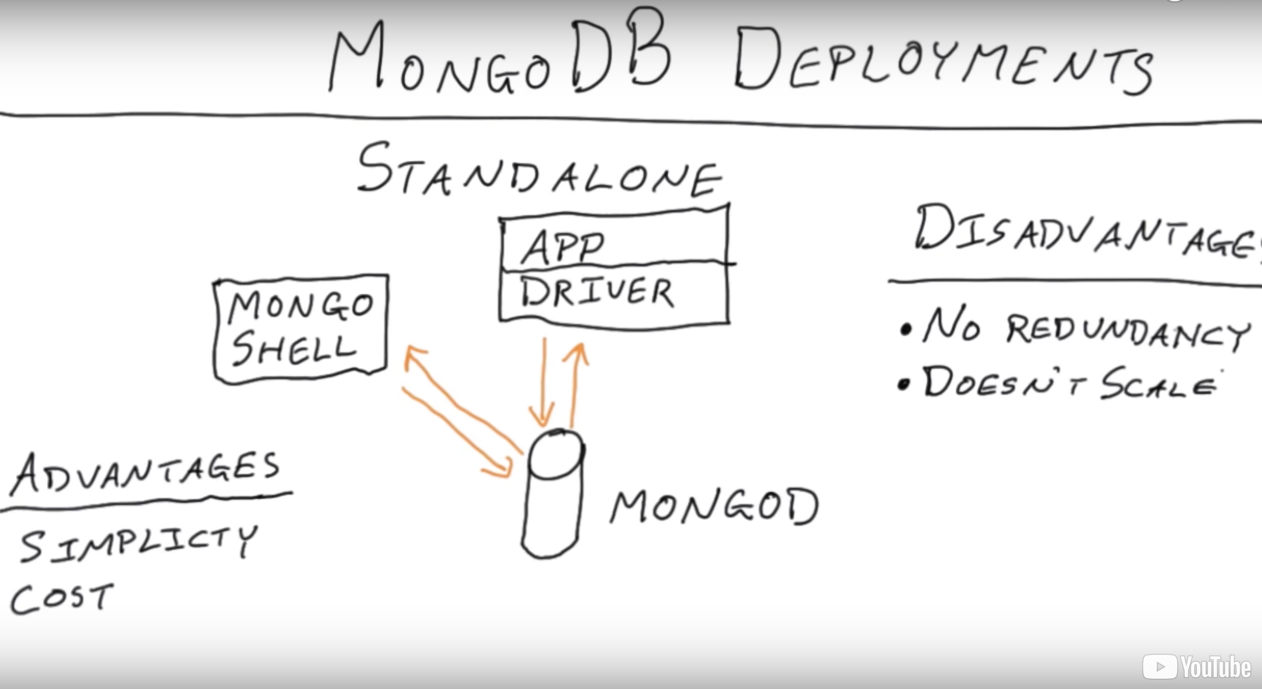
Q: When scaling out horizontally (adding more servers to contain your data), what are problems that arise as you go from, say, 1 commodity server to a few dozen?
The servers must communicate with one another eating up network bandwidth
The need for redundancy increases as the likelihood of some failure in the system per unit of time increase
SQL and Complex Transactions
In distributinig environment(scale horizontally to multiple servers), joins and complex transactions could be problems.
MongoDB tries to bypass these problems and create sth not rely on joins or transactions.
Q: What causes significant problems for SQL when you attempt to scale horizontally (to multiple servers)?
A: Joins and Transactions
Documents Overview
No joins and Transactions, so
different data model (key/value store ~ K -> V)
“document-oriented”
JSON
What are some advantages of representing our data using a JSON-like format?
JSON presents a flexible and concise framework for specifying queries as well as storing records.
JSON is language independent.
Installing MongoDB(mac)
download the mongoDB from official web site
unzip and set the environment variables in the .bash_profile
mkdir -p <the path to the place you store data, e.g. /data/db> chmod 777 <the path to the place you store data, e.g. /data/db>
startup the database with the dbpath
1
➜ ~ mongod --dbpath <the path to the place you store data, e.g. /data/db>
Tips You can put it into a script.
startup mongo shell to connect the mongodb server
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
➜ ~ mongo MongoDB shell version v3.6.2 connecting to: mongodb://127.0.0.1:27017 MongoDB server version: 3.6.2 Server has startup warnings: 2018-01-22T16:35:49.495+1100 I CONTROL [initandlisten] 2018-01-22T16:35:49.495+1100 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database. 2018-01-22T16:35:49.495+1100 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted. 2018-01-22T16:35:49.495+1100 I CONTROL [initandlisten] 2018-01-22T16:35:49.495+1100 I CONTROL [initandlisten] ** WARNING: This server is bound to localhost. 2018-01-22T16:35:49.495+1100 I CONTROL [initandlisten] ** Remote systems will be unable to connect to this server. 2018-01-22T16:35:49.495+1100 I CONTROL [initandlisten] ** Start the server with --bind_ip <address> to specify which IP 2018-01-22T16:35:49.495+1100 I CONTROL [initandlisten] ** addresses it should serve responses from, or with --bind_ip_all to 2018-01-22T16:35:49.495+1100 I CONTROL [initandlisten] ** bind to all interfaces. If this behavior is desired, start the 2018-01-22T16:35:49.495+1100 I CONTROL [initandlisten] ** server with --bind_ip 127.0.0.1 to disable this warning. 2018-01-22T16:35:49.495+1100 I CONTROL [initandlisten]
or you haven’t startup database server, so use –nodb
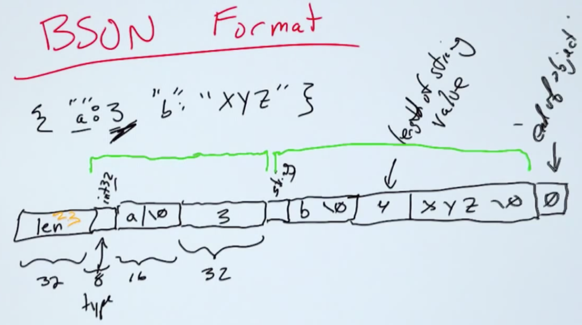
data types - stringer typing(and more types) than JSON (date datatype, bin data, ObjectId)
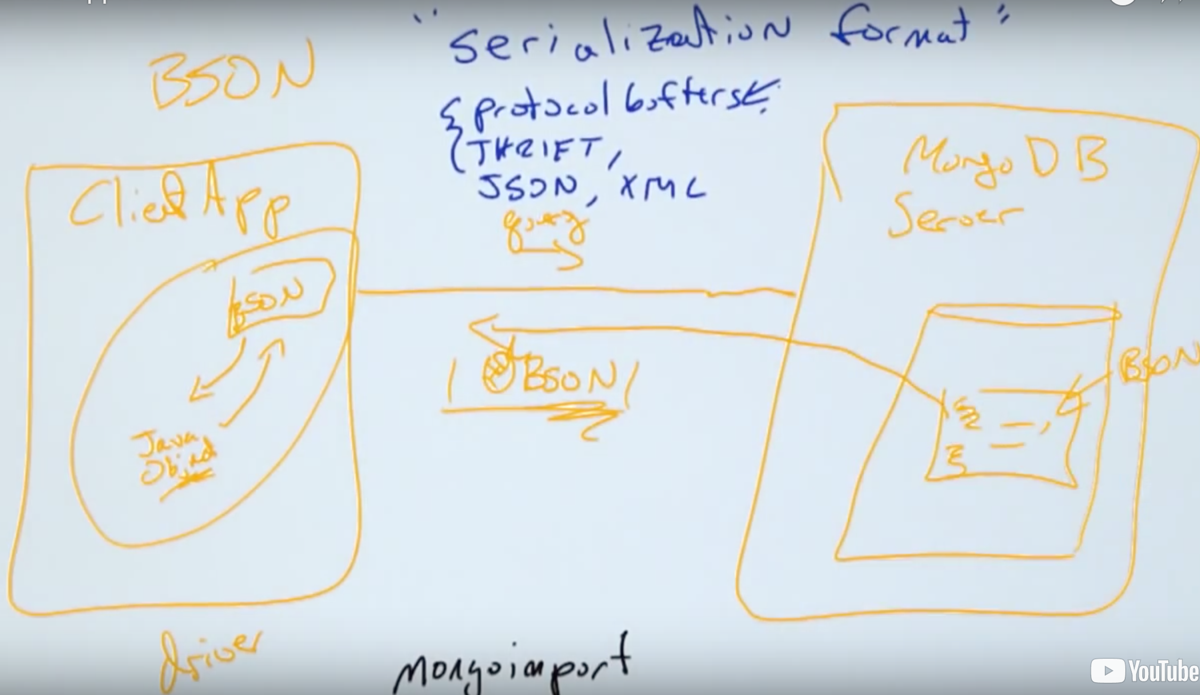
BSON and applications
For a typical client (a python client, for example) that is receiving the results of a query in BSON, would we convert from BSON to JSON to the client’s native data structures (for example, nested dictionaries and lists in Python), or would we convert from BSON straight to those native data structures?
BSON -> JSON -> Native data structures
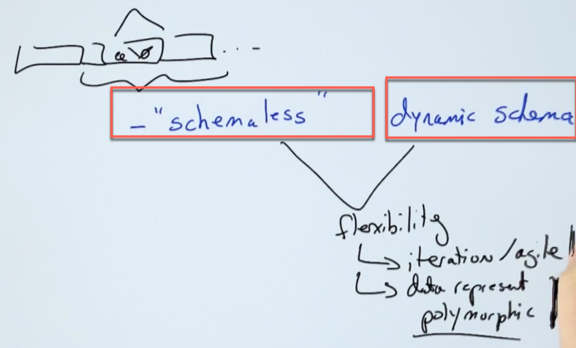
Dynamic Schema
True or False: MongoDB is schemaless because a schema isn’t very important in MongoDB
What is MongoDB shell?
startup your database
1
mongod --dbpath <your_data_path>
startup your mongodb shell to connect database
1
mongo
or assume no started database
1
mongo --nodb
By default, which database does the mongo shell connect to?
test
Mongoimport
You can use –help to see other commands and formats.
Newer versions of mongodb may show more verbose output during mongoimport.
If you do not specify a database, mongoimport will use test. If you do not specify a collection, it will use the filename.
The mongoimport utility can import what types of data?
json, csv, tsv
mongorestore vs. mongoimport
1 2 3
Utility mongorestore allows you to load data into the database. It requires a file (dump) that contains a BSON . Such a file can be created using different tools mongodump .
1 2 3 4
The second utility mongoimport allows you to import data from files in JSON, CSV or TSV. Better if the data file is created with the help mongoexport , though potentially possible to use other generators. Dump created with mongoexport not preserve typing, so you need to use it with the use of head and already working on databases better think twice.
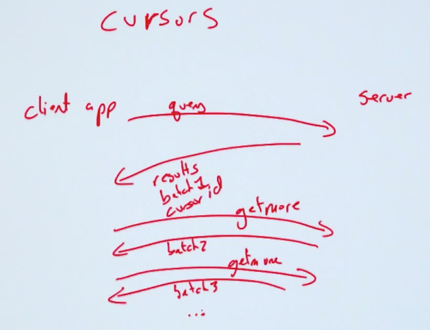
Cursors Introduction
1
mongo <servername>/<database_name>
1 2 3 4
➜ chapter_1_introduction mongo localhost/pcat MongoDB shell version v3.6.2 connecting to: mongodb://localhost:27017/pcat MongoDB server version: 3.6.2
MongoDB Enterprise > db.test.help() DBCollection help db.test.find().help() - show DBCursor help db.test.bulkWrite( operations, <optional params> ) - bulk execute write operations, optional parameters are: w, wtimeout, j db.test.count( query = {}, <optional params> ) - count the number of documents that matches the query, optional parameters are: limit, skip, hint, maxTimeMS db.test.copyTo(newColl) - duplicates collection by copying all documents to newColl; no indexes are copied. db.test.convertToCapped(maxBytes) - calls {convertToCapped:'test', size:maxBytes}} command db.test.createIndex(keypattern[,options]) db.test.createIndexes([keypatterns], <options>) db.test.dataSize() db.test.deleteOne( filter, <optional params> ) - delete first matching document, optional parameters are: w, wtimeout, j db.test.deleteMany( filter, <optional params> ) - delete all matching documents, optional parameters are: w, wtimeout, j db.test.distinct( key, query, <optional params> ) - e.g. db.test.distinct( 'x' ), optional parameters are: maxTimeMS db.test.drop() drop the collection db.test.dropIndex(index) - e.g. db.test.dropIndex( "indexName" ) or db.test.dropIndex( { "indexKey" : 1 } ) db.test.dropIndexes() db.test.ensureIndex(keypattern[,options]) - DEPRECATED, use createIndex() instead db.test.explain().help() - show explain help db.test.reIndex() db.test.find([query],[fields]) - query is an optional query filter. fields is optional set of fields to return. e.g. db.test.find( {x:77} , {name:1, x:1} ) db.test.find(...).count() db.test.find(...).limit(n) db.test.find(...).skip(n) db.test.find(...).sort(...) db.test.findOne([query], [fields], [options], [readConcern]) db.test.findOneAndDelete( filter, <optional params> ) - delete first matching document, optional parameters are: projection, sort, maxTimeMS db.test.findOneAndReplace( filter, replacement, <optional params> ) - replace first matching document, optional parameters are: projection, sort, maxTimeMS, upsert, returnNewDocument db.test.findOneAndUpdate( filter, update, <optional params> ) - update first matching document, optional parameters are: projection, sort, maxTimeMS, upsert, returnNewDocument db.test.getDB() get DB object associated with collection db.test.getPlanCache() get query plan cache associated with collection db.test.getIndexes() db.test.group( { key : ..., initial: ..., reduce : ...[, cond: ...] } ) db.test.insert(obj) db.test.insertOne( obj, <optional params> ) - insert a document, optional parameters are: w, wtimeout, j db.test.insertMany( [objects], <optional params> ) - insert multiple documents, optional parameters are: w, wtimeout, j db.test.mapReduce( mapFunction , reduceFunction , <optional params> ) db.test.aggregate( [pipeline], <optional params> ) - performs an aggregation on a collection; returns a cursor db.test.remove(query) db.test.replaceOne( filter, replacement, <optional params> ) - replace the first matching document, optional parameters are: upsert, w, wtimeout, j db.test.renameCollection( newName , <dropTarget> ) renames the collection. db.test.runCommand( name , <options> ) runs a db command with the given name where the first param is the collection name db.test.save(obj) db.test.stats({scale: N, indexDetails: true/false, indexDetailsKey: <index key>, indexDetailsName: <index name>}) db.test.storageSize() - includes free space allocated to this collection db.test.totalIndexSize() - size in bytes of all the indexes db.test.totalSize() - storage allocated for all data and indexes db.test.update( query, object[, upsert_bool, multi_bool] ) - instead of two flags, you can pass an object with fields: upsert, multi db.test.updateOne( filter, update, <optional params> ) - update the first matching document, optional parameters are: upsert, w, wtimeout, j db.test.updateMany( filter, update, <optional params> ) - update all matching documents, optional parameters are: upsert, w, wtimeout, j db.test.validate( <full> ) - SLOW db.test.getShardVersion() - only for use with sharding db.test.getShardDistribution() - prints statistics about data distribution in the cluster db.test.getSplitKeysForChunks( <maxChunkSize> ) - calculates split points over all chunks and returns splitter function db.test.getWriteConcern() - returns the write concern used for any operations on this collection, inherited from server/db ifset db.test.setWriteConcern( <write concern doc> ) - sets the write concern for writes to the collection db.test.unsetWriteConcern( <write concern doc> ) - unsets the write concern for writes to the collection db.test.latencyStats() - display operation latency histograms for this collection MongoDB Enterprise > db.test.find().help() find(<predicate>, <projection>) modifiers .sort({...}) .limit(<n>) .skip(<n>) .batchSize(<n>) - sets the number of docs to return per getMore .collation({...}) .hint({...}) .readConcern(<level>) .readPref(<mode>, <tagset>) .count(<applySkipLimit>) - total # of objects matching query. by default ignores skip,limit .size() - total # of objects cursor would return, honors skip,limit .explain(<verbosity>) - accepted verbosities are {'queryPlanner', 'executionStats', 'allPlansExecution'} .min({...}) .max({...}) .maxScan(<n>) .maxTimeMS(<n>) .comment(<comment>) .snapshot() .tailable(<isAwaitData>) .noCursorTimeout() .allowPartialResults() .returnKey() .showRecordId() - adds a $recordId field to each returned object
Cursor methods .toArray() - iterates through docs and returns an array of the results .forEach(<func>) .map(<func>) .hasNext() .next() .close() .objsLeftInBatch() - returns count of docs left in current batch (when exhausted, a new getMore will be issued) .itcount() - iterates through documents and counts them .getQueryPlan() - get query plans associated with shape. To get more info on query plans, call getQueryPlan().help(). .pretty() - pretty print each document, possibly over multiple lines
Download and install MongoDB from www.mongodb.org. Then run the database as a single server instance on your PC (that is, run the mongod binary). Then, run the administrative shell. From the shell prompt type db.isMaster().maxBsonObjectSize at the “>” prompt.
At this point you should have pcat.products loaded from the previous step. You can confirm this by running in the shell:
1 2 3 4
db.products.find() // or: db.products.count() // should print out "11"
Now, what query would you run to get all the products where brand equals the string “ACME”?
db.products.find({brand:"ACME"})
Next, how would you print out, in the shell, just the value in the “name” field, for all the product documents in the collection, without extraneous characters or braces, sorted alphabetically, ascending? (Check all that would apply.)
The answers were scrambled from person to person, so these won’t be in any particular order.
Correct answers:
1 2 3 4
var c = db.products.find( { }, { name : 1, _id : 0 } ).sort( { name : 1 } ); while( c.hasNext() ) { print( c.next().name); }
1 2
var c = db.products.find( { } ).sort( { name : 1 } ); c.forEach( function( doc ) { print( doc.name ) } );
Both of these are sorted ascending, and are printing only the value of name. The following answers are incorrect:
1
db.products.find( { }, { name : 1, _id : 0 } ).sort( { name : 1 } )
This is wrong because it prints each document, and does not remove the braces, the colons (“:”), or the field name.
1 2 3 4
var c = db.products.find( { } ).sort( { name : -1 } ); while( c.hasNext() ) { print( c.next().name); }
This is wrong because it is sorting by name in a descending order, not ascending order as specified in the question.
➜ chapter_2_crud_and_administrative_commands mongoimport --db pcat --collection test < test.json 2018-01-23T17:14:55.770+1100 connected to: localhost 2018-01-23T17:14:55.825+1100 imported 5 documents ➜ chapter_2_crud_and_administrative_commands mongo MongoDB shell version v3.6.2 connecting to: mongodb://127.0.0.1:27017 MongoDB server version: 3.6.2 Server has startup warnings: 2018-01-23T15:45:21.088+1100 I CONTROL [initandlisten] 2018-01-23T15:45:21.088+1100 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database. 2018-01-23T15:45:21.088+1100 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted. 2018-01-23T15:45:21.088+1100 I CONTROL [initandlisten] 2018-01-23T15:45:21.088+1100 I CONTROL [initandlisten] ** WARNING: This server is bound to localhost. 2018-01-23T15:45:21.088+1100 I CONTROL [initandlisten] ** Remote systems will be unable to connect to this server. 2018-01-23T15:45:21.088+1100 I CONTROL [initandlisten] ** Start the server with --bind_ip <address> to specify which IP 2018-01-23T15:45:21.088+1100 I CONTROL [initandlisten] ** addresses it should serve responses from, or with --bind_ip_all to 2018-01-23T15:45:21.088+1100 I CONTROL [initandlisten] ** bind to all interfaces. If this behavior is desired, start the 2018-01-23T15:45:21.088+1100 I CONTROL [initandlisten] ** server with --bind_ip 127.0.0.1 to disable this warning. 2018-01-23T15:45:21.088+1100 I CONTROL [initandlisten] 2018-01-23T15:45:21.088+1100 I CONTROL [initandlisten] 2018-01-23T15:45:21.088+1100 I CONTROL [initandlisten] ** WARNING: soft rlimits too low. Number of files is 256, should be at least 1000 MongoDB Enterprise > show dbs admin 0.000GB config 0.000GB create_lesson_db 0.000GB local 0.000GB m101 0.000GB m102 0.000GB pcat 0.000GB test 0.000GB video 0.000GB MongoDB Enterprise > use pcat switched to db pcat MongoDB Enterprise > show collections products products_bak test MongoDB Enterprise > t = db.test pcat.test MongoDB Enterprise > t.find() { "_id" : ObjectId("5a66d2df7fff967e89a41d75"), "x" : "hello" } { "_id" : 100, "x" : "hello" } { "_id" : 101, "x" : "hello" } { "_id" : ObjectId("5a66d2df7fff967e89a41d76"), "x" : "hello" } { "_id" : ObjectId("5a66d2df7fff967e89a41d77"), "x" : "hello" }
db.cars.update({_id:100},{$set:{available:1}}) would set the available field to 1.
Multi Update
1 2 3 4 5
db.collection.update( query_document , update_document , [ options_document ] ) where optional options_document has any one or more of the following optional parameters: upsert : true/false, multi : true/false, writeConcern: document
Which of the following are disadvantages to setting multi=false (as it is by default)?
Updates that the user may have intended to match multiple documents will exit prematurely, after only one update.
MongoDB Enterprise > var it = db.test.find(); it.forEach(function(o){db.test_bak.insert(o)}) MongoDB Enterprise > show collections products products_bak test test_bak
Suppose we have documents in the users collection of the form:
1 2 3 4 5 6 7 8 9 10
{ _id : ObjectId("50897dbb9b96971d287202a9"), name : "Jane", likes : [ "tennis", "golf" ], registered : false, addr : { city : "Lyon", country : "France" } }
How would we, in the mongo shell, delete all documents in the collection where city is “Lyon” and registered is false?
Enter answer here: db.users.remove({"addr.city":"Lyon","registered":false})
We specify a query, just like a find query, and the remove method deletes all documents that match the query. In place of remove, you can also use deleteMany, as of MongoDB 3.2.
Suppose we have documents in the users collection of the form:
1 2 3 4
{ _id : "Jane", likes : [ "tennis", "golf" ] }
How would we, in the mongo shell, add that this user likes “football”? We want to record this even if the user does not yet have a document. We also want to avoid having duplicate items in the “likes” field.
NOTE: Make sure to use the new syntax, which uses an options_document:
The update part uses $addToSet to insert the string “football” into the array. $push would almost work, but $addToSet is better because it prevents duplicate items from being added to the array.)
The third parameter is the options document, specifying {upsert: true}, so that if no document with _id “Jane” exists, MongoDB will insert this new document:
{ _id: "Jane", likes: [ "football" ] }
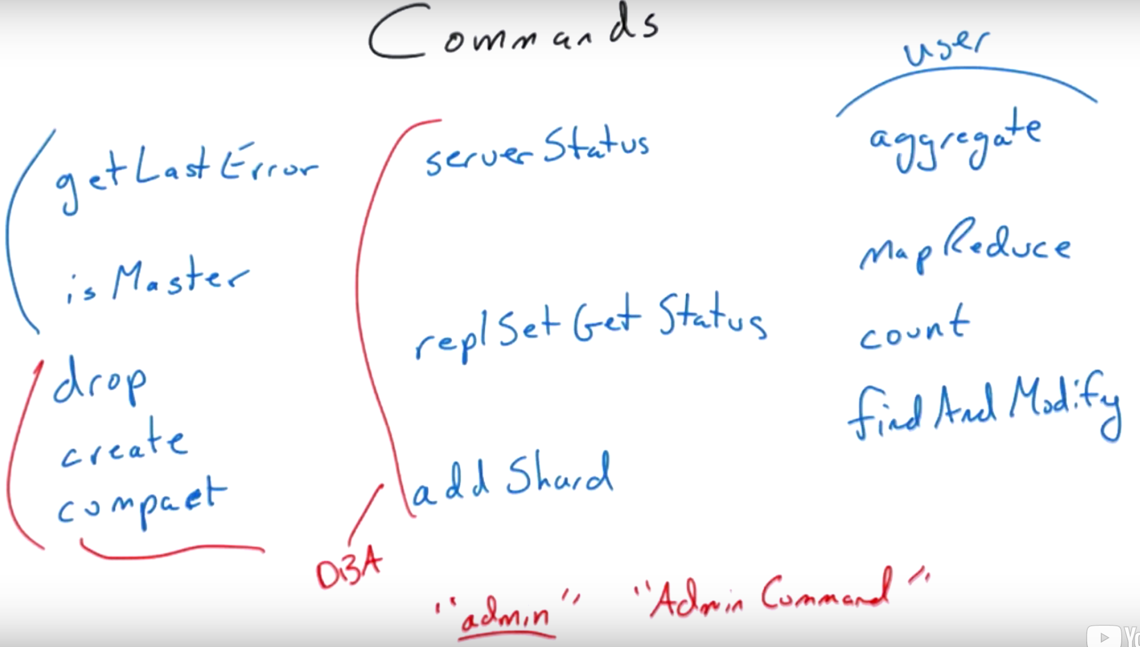
Wire Protocol
What is a comand in the mongo wire protocol?
Sometimes we refer to that as the “BSON wire Protocol”, whcih if you were writing a driver, for example, you would want to know all the details there.
We can do things like query, inserts, update, remove. There is also one more thing called “Get More” associated with an existing cursor. These are the basic building blocks of the wire protocol to manipulate the data.
Command is different from the above things. Commands are actually sent to the server as queries, where the client will send a query where the query expression actually is the command to the server. The server will run the command, and send back a response, which looks lke a query response that is a single document. The document will contain code, various results, and results of the command that was executed. So we are overloading the query operator in the wire protocol, and we do that. There is a special collection called $cmd, used for that under the covers. That’s all sort of internal stuffs.
Everything on the page is internal stuffs.
1 2 3 4 5 6 7 8
In computer networking, a wire protocol refers to a way of getting data from point to point: A wire protocol is needed if more than one application has to interoperate. It generally refers to protocols higher than the physical layer.[1] In contrast to transport protocols at the transport level (like TCP or UDP), the term "wire protocol" is used to describe a common way to represent information at the application level. It refers only to a common application layer protocol and not to a common object semantic[clarification needed] of the applications. Such a representation at application level needs a common infoset (e.g. XML) and a data binding (using e.g. a common encoding scheme like XSD).
1 2 3 4 5 6 7 8
Definition of: wire protocol (1) In a network, a wire protocol is the mechanism for transmitting data from point a to point b. The term is a bit confusing, because it sounds like layer 1 of the network, which physically places the bits "onto the wire." In some cases, it may refer to layer 1; however, it generally refers to higher layers, including Ethernet and ATM (layer 2) and even higher layer distributed object protocols such as SOAP, CORBA or RMI. See OSI model, communications protocol, data link protocol and distributed objects. (2) In an electronic system, a wire protocol refers to the control signals (start and stop data transfer) and architecture (serial, parallel, etc.) of the bus or channel.
True or false: db.collection.remove({}), which removes all messages in a collection, is the same as db.collection.drop(), which drops the collection.
False
Review of Commands
Homework 2.1
We will use the pcat.products collection from week 1. So start with that; if not already set up, import it:
mongoimport --drop -d pcat -c products products.json You can find products.json from the Download Handouts link.
In the shell, go to the pcat database. If you type:
1 2 3
use pcat; db.products.count() the shell should return 11.
Next, download homework2.js from the Download Handouts link. Run the shell with this script:
mongo --shell pcat homework2.js
First, make a mini-backup of the collection before we start modifying it. In the shell:
1 2 3 4
b = db.products_bak; db.products.find().forEach( function(o){ b.insert(o) } ) // check it worked: b.count() // should print 11
If you have any issues you can restore from “products_bak”; or, you can re-import with mongoimport. (You would perhaps need in that situation to empty the collection first or drop it; see the –drop option on mongoimport –help.)
In the shell, type:
homework.a()
What is the output? (The above will check that products_bak is populated.)
Enter answer here: 3.05
Homework 2.2
Add a new product to the products collection of this form:
Note: in general because of the automatic line continuation in the shell, you can cut/paste in the above and shouldn’t have to type it all out. Just enclose it in the proper statement(s) to get it added.
Next, load into a shell variable the object corresponding to
_id : ObjectId(“507d95d5719dbef170f15c00”)
Then change term_years to 3 for that document. (And update it in the database.) Then change over_rate for sms in limits to 0.01 from 0. Update that too. At the shell prompt type:
homework.b()
What is the output?
Enter answer here: 0.050.019031
Homework 2.3
How many products have a voice limit? (That is, have a voice field present in the limits subdocument.)
Input your answer below, (just a number, no other characters).
While you can parse this one by eye, please try to use a query that will do the work of counting it for you.
Just to clarify, the answer should be a number, not a document. There should be no brackets, spaces, quotation marks, etc.
Enter answer here:
3
Chapter 3: Performance
Welcome to Week 3
Storage Engines
Indexes
Storage Engine: Introduction
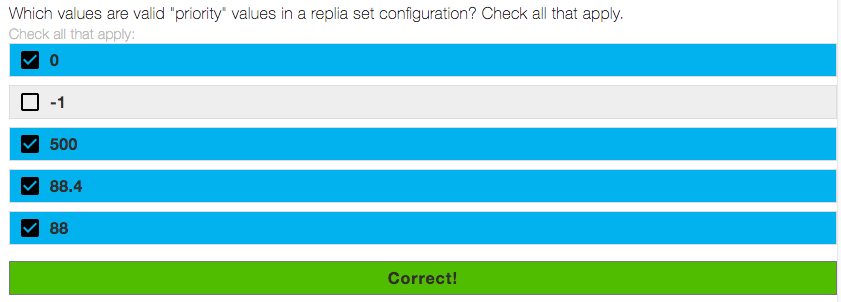
The storage engine directly determines which of the following? Check all that apply.
✔︎The data file format
Architecture of a cluster
The wire protocol for the drivers
✔︎Format of indexes
Answer
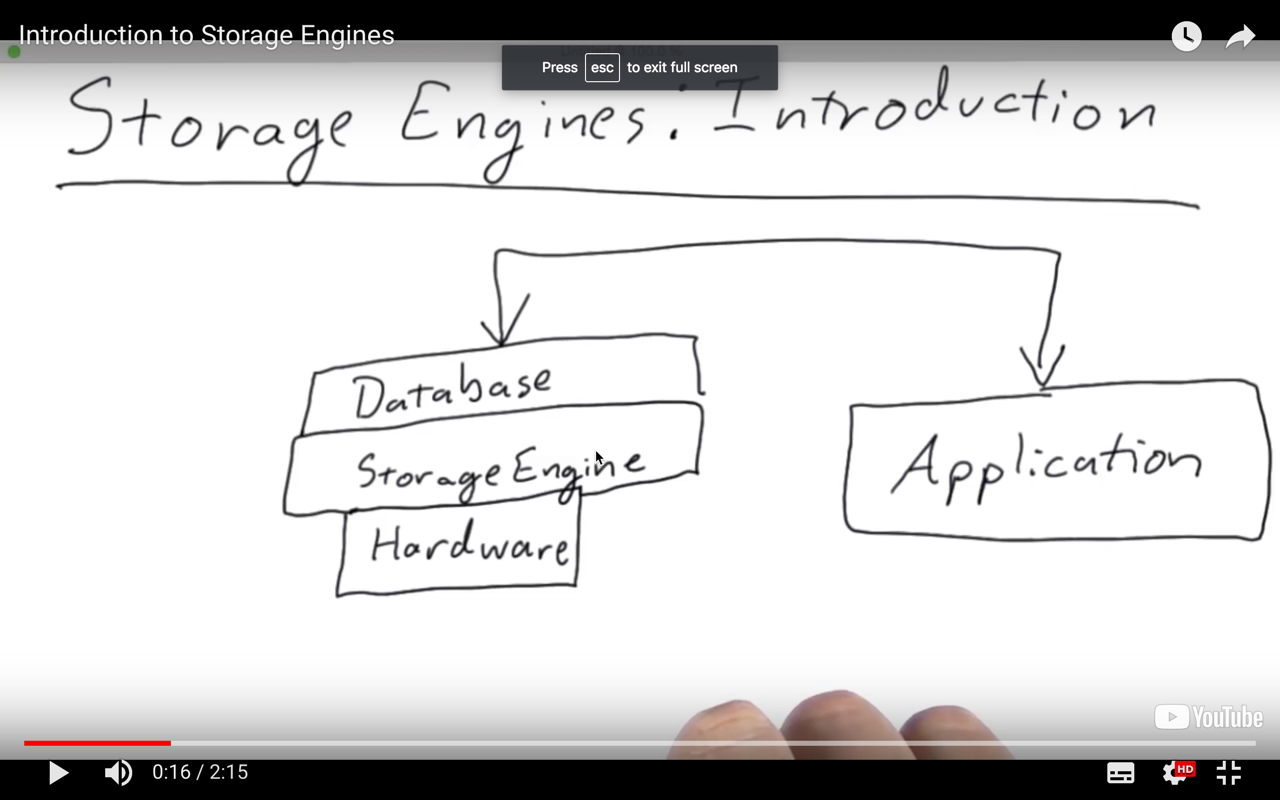
The storage engine handles the interface between the database and the hardware, and by hardware, we mean specifically memory and disk, and any representations of the data (or metadata) that is located there, which is to say the data and indexes.
The data file format - The data files’ format is determined by the storage engine, so this choice is correct. Different storage engines can implement different types of compression, and different ways of storing the BSON for mongoDB.
Architecture of a cluster - We picked false here, but you might argue with this choice. The architecture of the cluster is determined by interactions between servers, which communicate over the wire. Since the storage engine doesn’t affect the wire protocol, the server architecture could be exactly the same, which is why we went with false. Even so, one might argue that a good choice of storage engine should result in a smaller cluster to handle the same workload. If your gut was to go with true for this reason, that’s a defensible choice.
The wire protocol for the drivers - False. The wire protocol determines how servers communicate with each other, or with the applications. This is clearly outside of the storage engine.
Format of indexes - True. It may not be obvious when you first think about it, but indexes are controlled by the storage engine. For instance, MongoDB uses Btrees. With MongoDB 3.0, WiredTiger will be using B+ trees, with other formats expected to come in later releases.
Storage Engine: MMAPv1
MMAPv1: Introduction
Grew from original stroage engine
uses mmap system call
default S.E. in MongoDB 3.0 or use –storageEngine=mmapv1
➜ workspace08 chmod 777 /Users/allen/Documents/Code/workspace08/data/db-MMAPv1 ➜ workspace08 mongod --dbpath /Users/allen/Documents/Code/workspace08/data/db-MMAPv1 --storageEngine=mmapv1 2018-01-29T20:41:34.708+1100 I CONTROL [initandlisten] MongoDB starting : pid=7498 port=27017 dbpath=/Users/allen/Documents/Code/workspace08/data/db-MMAPv1 64-bit host=AL.local 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] db version v3.6.2 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] git version: 489d177dbd0f0420a8ca04d39fd78d0a2c539420 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] OpenSSL version: OpenSSL 0.9.8zh 14 Jan 2016 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] allocator: system 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] modules: enterprise 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] build environment: 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] distarch: x86_64 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] target_arch: x86_64 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] options: { storage: { dbPath: "/Users/allen/Documents/Code/workspace08/data/db-MMAPv1", engine: "mmapv1" } } 2018-01-29T20:41:34.719+1100 I JOURNAL [initandlisten] journal dir=/Users/allen/Documents/Code/workspace08/data/db-MMAPv1/journal 2018-01-29T20:41:34.720+1100 I JOURNAL [initandlisten] recover : no journal files present, no recovery needed 2018-01-29T20:41:34.737+1100 I JOURNAL [durability] Durability thread started 2018-01-29T20:41:34.737+1100 I JOURNAL [journal writer] Journal writer thread started 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** WARNING: This server is bound to localhost. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** Remote systems will be unable to connect to this server. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** Start the server with --bind_ip <address> to specify which IP 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** addresses it should serve responses from, or with --bind_ip_all to 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** bind to all interfaces. If this behavior is desired, start the 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** server with --bind_ip 127.0.0.1 to disable this warning. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] 2018-01-29T20:41:34.766+1100 I FTDC [initandlisten] Initializing full-time diagnostic data capture with directory '/Users/allen/Documents/Code/workspace08/data/db-MMAPv1/diagnostic.data' 2018-01-29T20:41:34.767+1100 I NETWORK [initandlisten] waiting for connections on port 27017
can use db.serverStatus() to check strage engine
1
MongoDB Enterprise > db.serverStatus()
Quiz To understand MMAPv1, it is important to know that it: Maps data files directly into virtual memory.
➜ workspace08 chmod 777 /Users/allen/Documents/Code/workspace08/data/db-MMAPv1 ➜ workspace08 mongod --dbpath /Users/allen/Documents/Code/workspace08/data/db-MMAPv1 --storageEngine=mmapv1 2018-01-29T20:41:34.708+1100 I CONTROL [initandlisten] MongoDB starting : pid=7498 port=27017 dbpath=/Users/allen/Documents/Code/workspace08/data/db-MMAPv1 64-bit host=AL.local 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] db version v3.6.2 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] git version: 489d177dbd0f0420a8ca04d39fd78d0a2c539420 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] OpenSSL version: OpenSSL 0.9.8zh 14 Jan 2016 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] allocator: system 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] modules: enterprise 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] build environment: 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] distarch: x86_64 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] target_arch: x86_64 2018-01-29T20:41:34.709+1100 I CONTROL [initandlisten] options: { storage: { dbPath: "/Users/allen/Documents/Code/workspace08/data/db-MMAPv1", engine: "mmapv1" } } 2018-01-29T20:41:34.719+1100 I JOURNAL [initandlisten] journal dir=/Users/allen/Documents/Code/workspace08/data/db-MMAPv1/journal 2018-01-29T20:41:34.720+1100 I JOURNAL [initandlisten] recover : no journal files present, no recovery needed 2018-01-29T20:41:34.737+1100 I JOURNAL [durability] Durability thread started 2018-01-29T20:41:34.737+1100 I JOURNAL [journal writer] Journal writer thread started 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** WARNING: This server is bound to localhost. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** Remote systems will be unable to connect to this server. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** Start the server with --bind_ip <address> to specify which IP 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** addresses it should serve responses from, or with --bind_ip_all to 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** bind to all interfaces. If this behavior is desired, start the 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** server with --bind_ip 127.0.0.1 to disable this warning. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] 2018-01-29T20:41:34.766+1100 I FTDC [initandlisten] Initializing full-time diagnostic data capture with directory '/Users/allen/Documents/Code/workspace08/data/db-MMAPv1/diagnostic.data' 2018-01-29T20:41:34.767+1100 I NETWORK [initandlisten] waiting for connections on port 27017
➜ ~ mongo localhost MongoDB shell version v3.6.2 connecting to: mongodb://127.0.0.1:27017/localhost MongoDB server version: 3.6.2 Server has startup warnings: 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** WARNING: This server is bound to localhost. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** Remote systems will be unable to connect to this server. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** Start the server with --bind_ip <address> to specify which IP 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** addresses it should serve responses from, or with --bind_ip_all to 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** bind to all interfaces. If this behavior is desired, start the 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] ** server with --bind_ip 127.0.0.1 to disable this warning. 2018-01-29T20:41:34.737+1100 I CONTROL [initandlisten] MongoDB Enterprise > show dbs admin 0.078GB config 0.078GB local 0.078GB MongoDB Enterprise >
2
1 2 3 4 5 6 7 8 9 10
MongoDB Enterprise > use test switched to db test MongoDB Enterprise > db.foo.insert({a : 1}) WriteResult({ "nInserted" : 1 }) MongoDB Enterprise > show dbs admin 0.078GB config 0.078GB local 0.078GB test 0.078GB MongoDB Enterprise >
MongoDB Enterprise > show dbs admin 0.078GB config 0.078GB local 0.078GB test 3.952GB MongoDB Enterprise > use test switched to db test MongoDB Enterprise > db.foo.stats() { "ns" : "test.foo", "size" : 2080768000, "count" : 1024000, "avgObjSize" : 2032, "numExtents" : 20, "storageSize" : 2140639232, "lastExtentSize" : 560488448, "paddingFactor" : 1, "paddingFactorNote" : "paddingFactor is unused and unmaintained in 3.0. It remains hard coded to 1.0 for compatibility only.", "userFlags" : 1, "capped" : false, "nindexes" : 1, "totalIndexSize" : 28583296, "indexSizes" : { "_id_" : 28583296 }, "ok" : 1 } MongoDB Enterprise >
Terminal 3.
1
1 2 3 4 5 6 7 8 9 10 11 12 13 14
➜ db-MMAPv1 ls -lah total 98616 drwxrwxrwx 12 allen staff 384B 29 Jan 20:41 . drwxr-xr-x 4 root staff 128B 29 Jan 20:17 .. -rw------- 1 allen staff 64M 29 Jan 20:24 admin.0 -rw------- 1 allen staff 16M 29 Jan 20:24 admin.ns -rw------- 1 allen staff 64M 29 Jan 20:29 config.0 -rw------- 1 allen staff 16M 29 Jan 20:29 config.ns drwx------ 5 allen staff 160B 29 Jan 20:44 diagnostic.data drwx------ 3 allen staff 96B 29 Jan 20:41 journal -rw------- 1 allen staff 64M 29 Jan 20:42 local.0 -rw------- 1 allen staff 16M 29 Jan 20:42 local.ns -rw------- 1 allen staff 5B 29 Jan 20:41 mongod.lock -rw------- 1 allen staff 69B 29 Jan 20:23 storage.bson
2
After creating test, you can see files about test below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
➜ db-MMAPv1 ls -lah total 131472 drwxrwxrwx 15 allen staff 480B 29 Jan 20:48 . drwxr-xr-x 4 root staff 128B 29 Jan 20:17 .. drwx------ 2 allen staff 64B 29 Jan 20:48 _tmp -rw------- 1 allen staff 64M 29 Jan 20:24 admin.0 -rw------- 1 allen staff 16M 29 Jan 20:24 admin.ns -rw------- 1 allen staff 64M 29 Jan 20:29 config.0 -rw------- 1 allen staff 16M 29 Jan 20:29 config.ns drwx------ 5 allen staff 160B 29 Jan 20:49 diagnostic.data drwx------ 4 allen staff 128B 29 Jan 20:48 journal -rw------- 1 allen staff 64M 29 Jan 20:42 local.0 -rw------- 1 allen staff 16M 29 Jan 20:42 local.ns -rw------- 1 allen staff 5B 29 Jan 20:41 mongod.lock -rw------- 1 allen staff 69B 29 Jan 20:23 storage.bson -rw------- 1 allen staff 64M 29 Jan 20:48 test.0 -rw------- 1 allen staff 16M 29 Jan 20:48 test.ns
var emptyString = 'asdf'; emptyString = emptyString.pad(1000); // make it bigger. // make one thousand copies of our document in an array. listOfDocs = [] for (i=0; i<kmax; i++) { listOfDocs.push({ _id: 0, a: 0, b : 0, c : 0, d : emptyString }); }; // one_thousand_docs is now built.
db.dropDatabase(); // start with a clean slate. // db.createCollection("foo", {noPadding: true}) for (i=0; i<imax; i++) { for(j=0; j<jmax; j++) { for (k=0; k<1000; k++) { setValues(listOfDocs[k], i, j, k) }; db.foo.insert(listOfDocs) // breaks up if larger than 1000. } }
1 2 3 4
➜ chapter_3_performance mongo loadDatabase_5521db56d8ca39427d77dfd3.js MongoDB shell version v3.6.2 connecting to: mongodb://127.0.0.1:27017 MongoDB server version: 3.6.2
➜ db-MMAPv1 ls -lah total 4283656 drwxrwxrwx 20 allen staff 640B 29 Jan 21:00 . drwxr-xr-x 4 root staff 128B 29 Jan 20:17 .. drwx------ 2 allen staff 64B 29 Jan 21:00 _tmp -rw------- 1 allen staff 64M 29 Jan 20:24 admin.0 -rw------- 1 allen staff 16M 29 Jan 20:24 admin.ns -rw------- 1 allen staff 64M 29 Jan 20:29 config.0 -rw------- 1 allen staff 16M 29 Jan 20:29 config.ns drwx------ 5 allen staff 160B 29 Jan 21:02 diagnostic.data drwx------ 4 allen staff 128B 29 Jan 21:00 journal -rw------- 1 allen staff 64M 29 Jan 20:42 local.0 -rw------- 1 allen staff 16M 29 Jan 20:42 local.ns -rw------- 1 allen staff 5B 29 Jan 20:41 mongod.lock -rw------- 1 allen staff 69B 29 Jan 20:23 storage.bson -rw------- 1 allen staff 64M 29 Jan 21:00 test.0 -rw------- 1 allen staff 128M 29 Jan 21:00 test.1 -rw------- 1 allen staff 256M 29 Jan 21:00 test.2 -rw------- 1 allen staff 512M 29 Jan 21:00 test.3 -rw------- 1 allen staff 1.0G 29 Jan 21:00 test.4 -rw------- 1 allen staff 2.0G 29 Jan 21:00 test.5 -rw------- 1 allen staff 16M 29 Jan 21:00 test.ns
Storage Engine: WiredTiger
New in MongoDB 3.0
First pluggable storage engine
Features
Document Level Locking
Compression
Locks some pitfalls of MMAPv1
Performance gains
Built separately from MongoDB
Used by other DB’s
Open Source
WT internals
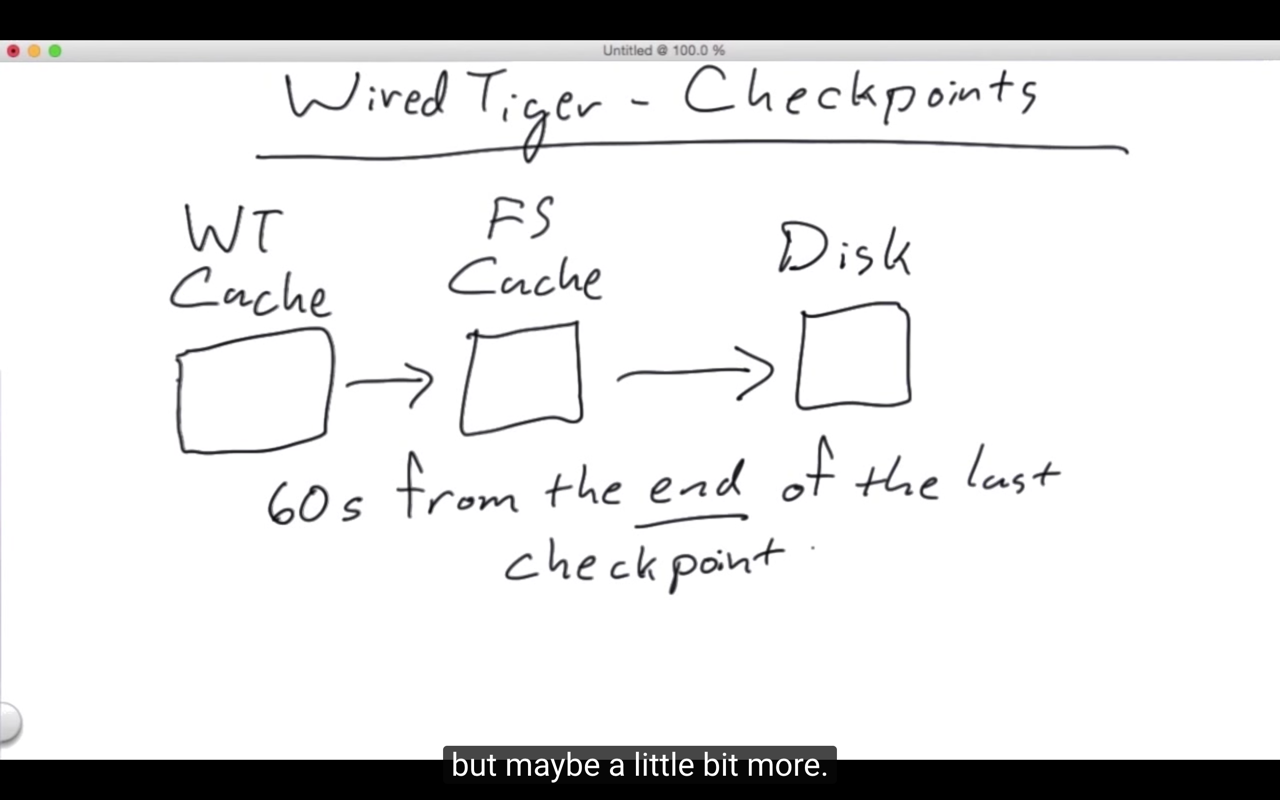
Stores data in btrees
Writes are initially separate, incorporated later
Two caches
WT Cache - 1/2 of RAM(default)
FS(File System) Cache
WT-Document Level Locking
Wired Tiiger - Compression
* Snappy(default)-fast
* Zlib - more compression
* none
var emptyString = 'asdf'; emptyString = emptyString.pad(1000); // make it bigger. // make one thousand copies of our document in an array. listOfDocs = [] for (i=0; i<kmax; i++) { listOfDocs.push({ _id: 0, a: 0, b : 0, c : 0, d : emptyString }); }; // one_thousand_docs is now built.
db.dropDatabase(); // start with a clean slate. // db.createCollection("foo", {noPadding: true}) for (i=0; i<imax; i++) { for(j=0; j<jmax; j++) { for (k=0; k<1000; k++) { setValues(listOfDocs[k], i, j, k) }; db.foo.insert(listOfDocs) // breaks up if larger than 1000. } }
1 2 3 4
➜ chapter_3_performance mongo loadDatabase_5521db56d8ca39427d77dfd3.js MongoDB shell version v3.6.2 connecting to: mongodb://127.0.0.1:27017 MongoDB server version: 3.6.2
Quiz
1 2 3 4
The WiredTiger storage engine brings which of the following to MongoDB? Check all that apply. ✔︎Compression ✔︎Document-;ebe; concurrency control Replication
keys(document) A document that contains the field and value pairs where the field is the index key and the value describes the type of index for that field. For an ascending index on a field, specify a value of 1; for descending index, specify a value of -1.
MongoDB supports several different index types including text, geospatial, and hashed indexes. See index types for more information.
Starting in 3.6, you cannot specify * as the index name.
What will happen if an index is created on a field that does not exist in any of the documents in the collection?
MongoDB will create the index without any warning.
Collection Scans
Subtitles from git.
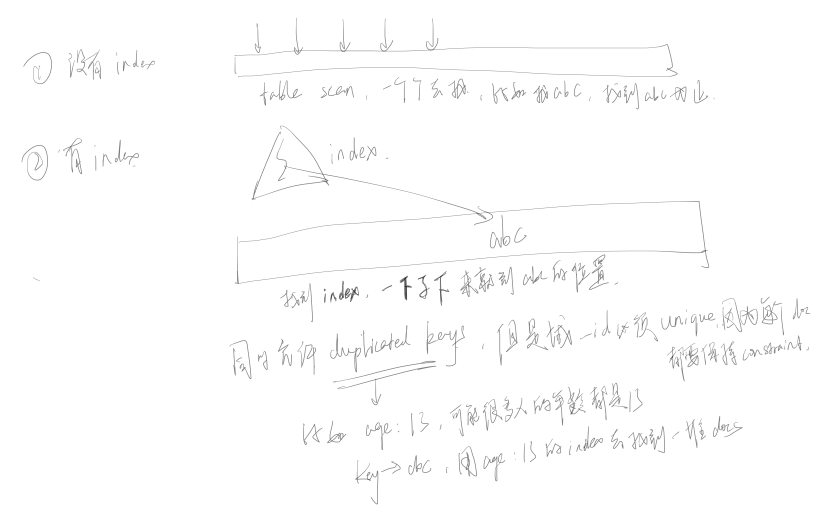
So why do we create these indexes?And if you have a collection with all these documents in them. Say 1 billion documents or even a million or thousand and you want to find a specific document very quickly.
For example, {_id: …, value: abc} we are looking for…
If we don’t have indexes, the database will do the table scan. Use the relational term - it will do the collection scan sequentially through the whole thing looking for matches to this, and that will be slow if the collection is large. However, if we have index and we will have an index on the id generally as id index is automatically created for a colleciton. That is here.
It you want to find abc value you just descend down to find a abc and there will be a pointer to the right record or records. Duplicated keys are allowed in Mongo indexes not in id index because of unique key constraint, but you could imagine having an index on say you know age and maybe somebody’s ages 33. It is the example I keep using obviously there could be a lot of people with the same age we can index, and then in the index of the entries these kinds of key to dock load pairs there be one for each of two documents that has this age 33
Index Notes
notes on indexes
keys can be any type
_id index is automatic (unique)
other than _id, explicitly declared
automatically used
can index array contents
{likes:[“tennis”, “golf”]} we going to add a key “tennis” pointing to this documents, also a key “golf” pointing to this document. These are called multikeys. Just keep in mind that an entry will be put in the B-tree for this likes index. It will be 100 keys in the B-tree, which would be a lot. but presumably if you are doing that, you are doing that for a reason.
can index subdocuments and subfields
{wind:{direction:”N”, speed:12.2}} in generall , it is better to build a compound index, such as createIndex({“wind.direction”: 1,”wind.speed”:1}), which be for $elemMatch operator
fieldnames are not in the index, because it saves space
1 2 3 4 5
{ __, __, age:33 }
index 33 points to the above document
mongodb can have keys of different types
A MongoDB index can have keys of different types (i.e., ints, dates, string). True
Note:
Lecture Notes In this video, Dwight mentions that the index is used automatically if it is present. This is no longer always true if you are sorting using a sparse index, but remains true otherwise. He also uses the ensureIndex command, which is deprecated as of MongoDB 3.0 in favor of createIndex.
If an index is unique AND sparse, can 2 documents whichdo not include the field that is indexed exist in the same collection? Choose the best answer: `yes`
{"words":"pig sing in A"} {"words":"pig dance in A"} {"words":"cat walk in B"} {"words":"cat dance in D"} {"words":"dog walk in A"} {"words":"pig dance in D"} {"words":"dog dance in C"} {"words":"cat run in A"} {"words":"pig dance in D"} {"words":"dog sing in C"} {"words":"pig run in C"} {"words":"dog dance in A"} {"words":"dog run in C"} {"words":"dog sing in C"} {"words":"pig run in D"} {"words":"dog walk in C"} {"words":"pig dance in B"} {"words":"dog sing in C"} {"words":"dog sing in B"} {"words":"pig dance in A"} {"words":"pig dance in D"} {"words":"dog dance in D"} {"words":"cat walk in D"} {"words":"dog sing in B"} {"words":"cat sing in D"} {"words":"pig walk in C"} {"words":"pig run in B"}
1 2 3
making-sentences mongoimport --db test --collection sentences sentences.json 2018-01-30T15:33:41.807+1100 connected to: localhost 2018-01-30T15:33:41.810+1100 imported 27 documents
Which of the following documents will be returned, assuming they are in the movies collection? Check all that apply.
Check all that apply:
✔︎{ "title" : "The Big Lebowski", star : "Jeff Bridges" }
✔︎{ "title" : "Big", star : "Tom Hanks" }
✔︎{ "title" : "Big Fish", star : "Ewan McGregor" }
Background Index Creation
As of MongoDB 2.6, background index creation will occur on secondaries as well as the primary when a background index is created on the primary of a replica set.
Creation Options
dropDups: true (equal to unique: true)
background: true
- bg operation on primary
- fg on secondaries
- slower than foreground
- foreground "peaks" more
- not done yet!
(be careful to use this)
(not understand yet)
Explain Plans
Explain
See which indexes are used in a query
Looks at the following queries
aggregate
find()
count()
remove()
update()
group()
make a collection
1 2 3 4 5 6 7
for (i = 0; i < 100; i++) { for (j = 0; j < 100; j++) { for (k = 0; k < 100; k++) { db.example.insert({ a : i, b : j, c : k, _id : (100 * 100 * i + 100 * j + k) }); } } }
What would need to be touched in order to fulfill the query?
Only the index needs to be touched to fully execute the query (the find() statement).
✔︎The index and some documents need to be touched.
Answer
The answer is that both the index and the documents need to be touched.
While the index is all that’s required to specify the document that matches the query, we’re asking for the entire document, which may contain fields that are not included in the index. Therefore, we need to touch that entire document.
Read & Write Recap
generally, more indexes -> fast reads
generally, more indexes -> slower writes
faster to build an index post import than pre import (imagine you’re asked to import a bunch of data into a new collection and that collection is going to have seven indexes after it’s been loaded. It will be faster to create the indexes after you do the initial data load than to create the indexes first. If you create the indexes first, all those key insertions into all those trees, B trees will be happening as the bulk import progresses. If you build all the indexes at the end, they can built in a bach mode bottom up, except for the ID index which will be generated automatically in the whole time)
Quiz Which ops are safe to kill (without any special effort or cleanup or implications later beyond the obvious): ✔︎A query ✔︎A findAndModify on a primary ? ✔︎A foreground create index building on a primary ? A foreground create index building on a secondary ? A compact command job
True or False: The system profiler is on by default.
Answer: False
mongostat and mongotop
Lecture Notes In this lecture, you can see the Mongostat output. While this remains current for MMAPv1, it looks a bit different for WiredTiger, which lacks idx miss, mapped, and faults, but adds % used and % dirty to describe the state of the WiredTiger cache. Here is our documentation if you are curious to learn more.
Homework 3.1
Download Handouts: performance__m102_performance_reorg_537a56c08bb48b7c467a20d3.zip Start a mongod server instance (if you still have a replica set, that would work too).
Next, download the handout and run:
mongo --shell localhost/performance performance.js homework.init() Build an index on the “active” and “tstamp” fields. You can verify that you’ve done your job with
db.sensor_readings.getIndexes() When you are done, run:
homework.a() and enter the numeric result below (no spaces).
Note: if you would like to try different indexes, you can use db.sensor_readings.dropIndexes() to drop your old index before creating a new one. (For this problem you will only need one index beyond the _id index which is present by default.)
➜ performance__m102_performance_reorg_537a56c08bb48b7c467a20d3 mongo --shell localhost/performance performance.js MongoDB shell version v3.6.2 connecting to: mongodb://localhost:27017/performance MongoDB server version: 3.6.2 type"help"forhelp Server has startup warnings: 2018-01-30T10:17:32.567+1100 I CONTROL [initandlisten] 2018-01-30T10:17:32.567+1100 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database. 2018-01-30T10:17:32.567+1100 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted. 2018-01-30T10:17:32.567+1100 I CONTROL [initandlisten] 2018-01-30T10:17:32.567+1100 I CONTROL [initandlisten] ** WARNING: This server is bound to localhost. 2018-01-30T10:17:32.567+1100 I CONTROL [initandlisten] ** Remote systems will be unable to connect to this server. 2018-01-30T10:17:32.567+1100 I CONTROL [initandlisten] ** Start the server with --bind_ip <address> to specify which IP 2018-01-30T10:17:32.567+1100 I CONTROL [initandlisten] ** addresses it should serve responses from, or with --bind_ip_all to 2018-01-30T10:17:32.567+1100 I CONTROL [initandlisten] ** bind to all interfaces. If this behavior is desired, start the 2018-01-30T10:17:32.567+1100 I CONTROL [initandlisten] ** server with --bind_ip 127.0.0.1 to disable this warning. 2018-01-30T10:17:32.567+1100 I CONTROL [initandlisten] MongoDB Enterprise > homework.init() { "connectionId" : 14, "n" : 0, "syncMillis" : 0, "writtenTo" : null, "err" : null, "ok" : 1 } still working... { "connectionId" : 14, "updatedExisting" : true, "n" : 20000, "syncMillis" : 0, "writtenTo" : null, "err" : null, "ok" : 1 } count: 20000 MongoDB Enterprise > db.sensor_readings.getIndexes() [ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "performance.sensor_readings" } ] MongoDB Enterprise > db.sensor_readings.createIndex({"active":1, "tstamp":1}) { "createdCollectionAutomatically" : false, "numIndexesBefore" : 1, "numIndexesAfter" : 2, "ok" : 1 } MongoDB Enterprise > db.sensor_readings.getIndexes() [ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "performance.sensor_readings" }, { "v" : 2, "key" : { "active" : 1, "tstamp" : 1 }, "name" : "active_1_tstamp_1", "ns" : "performance.sensor_readings" } ] MongoDB Enterprise > homework.a() 6
Homework 3.2
use currentOp()killOp(opid)
For this homework, you will need to use version 3.2 or later of MongoDB.
In a mongo shell run homework.b(). This will run in an infinite loop printing some output as it runs various statements against the server.
We’ll now imagine that on this system a user has complained of slowness and we suspect there is a slow operation running. Find the slow operation and terminate it.
In order to do this, you’ll want to open a second window (or tab) and there, run a second instance of the mongo shell, with something like:
Keep the other shell with homework.b() going while this is happening. Once you have eliminated the slow operation, run (on your second tab):
homework.c() and enter the output below. Once you have it right and are ready to move on, ctrl-c (terminate) the shell that is still running the homework.b() function.
If that looks somewhat familiar, that’s because it’s (nearly) the same command you used to import the pcat.products collection for Homework 2.1, with the only difference in the command being that it will drop the collection if it’s already present. This version of the collection, however, contains the state of the collection as it would exist once you’ve solved all of the homework of chapter 2.
Next, go into the pcat database.
mongo pcat
Create an index on the products collection for the field, “for”.
After creating the index, do a find() for products that work with an “ac3” phone (“ac3” is present in the “for” field).
Q1: How many products match this query?
Q2: Run the same query, but this time do an explain(). How many documents were examined?
Q3: Does the explain() output indicate that an index was used?
Check all that apply:
Q1: 4 Q2: 4 Q3: Yes
Homework 3.4
Which of the following are available in WiredTiger but not in MMAPv1? Check all that apply.
✔︎Document level locking
✔︎Data compression
Indexes
Collection level locking
Covered Queries
Chapter 4: Replication
Introduction to Week4
Replication
Durability
Availability
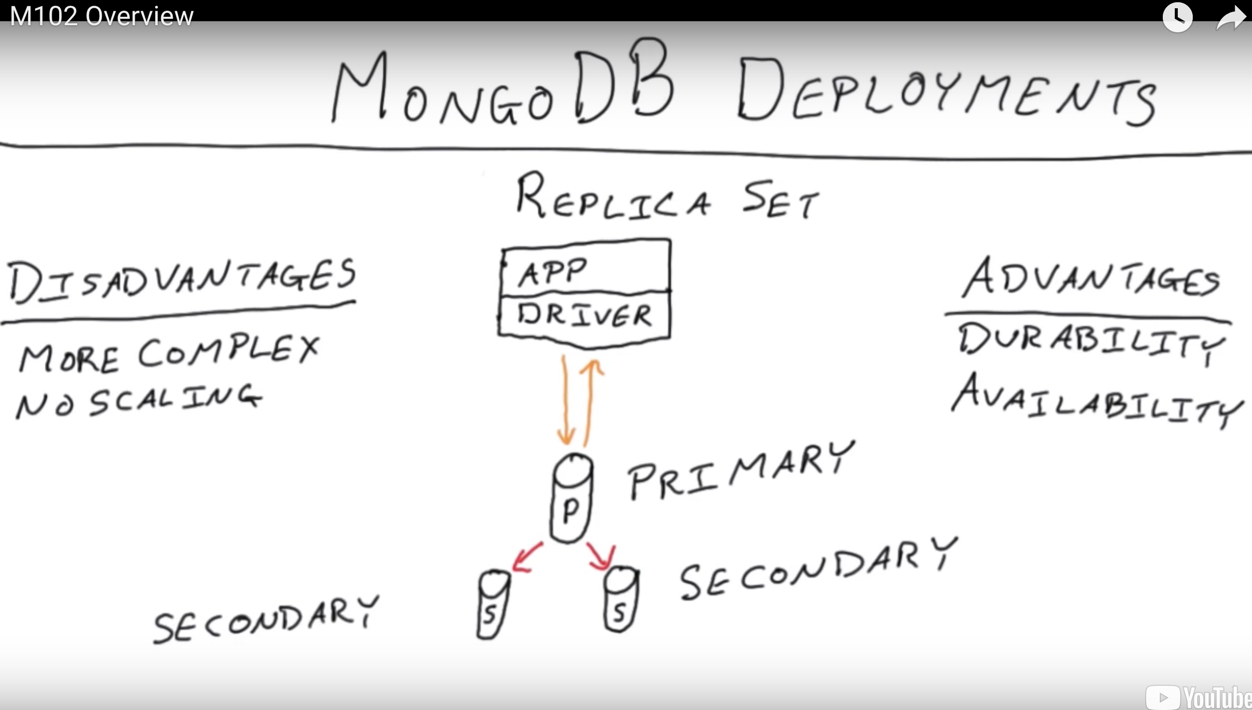
Replication Overview
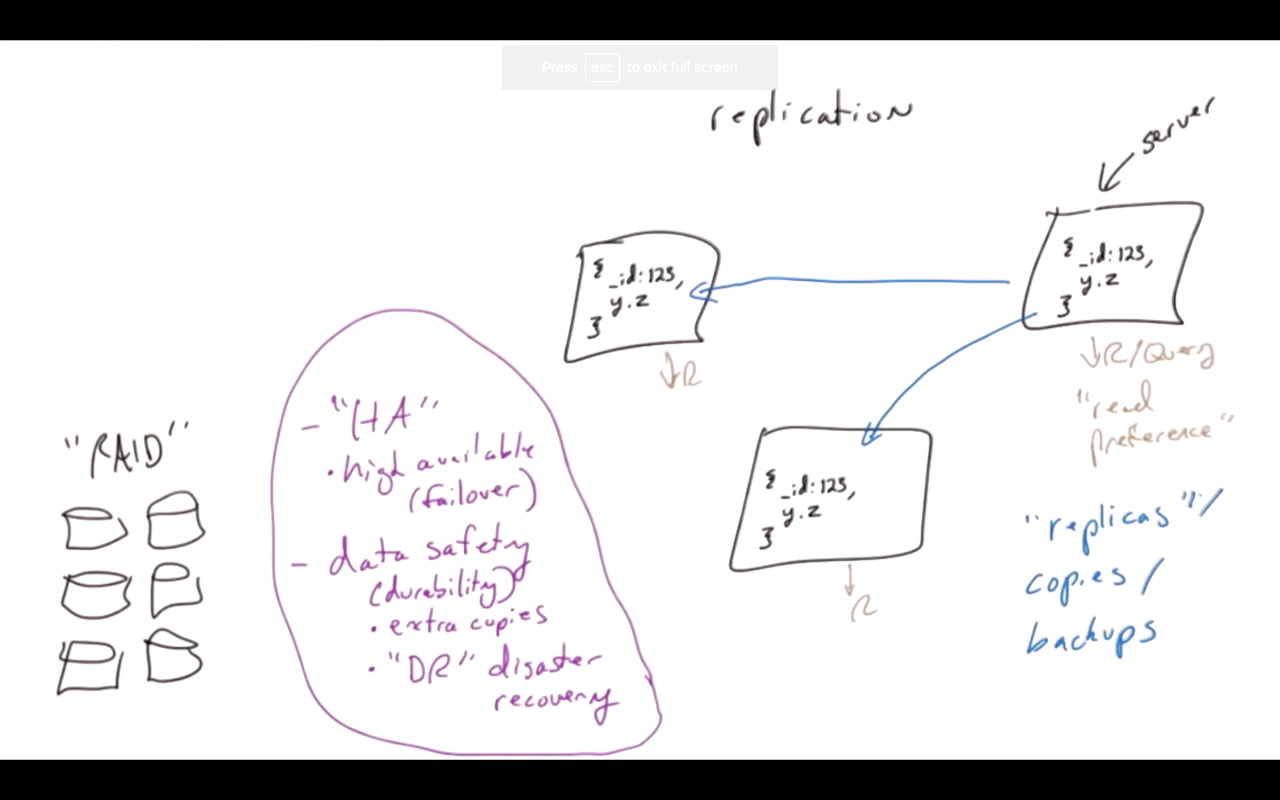
Replication is really important in the way you build up clusters in MongoDB. It is kind of very core to the product and the notion of replication in MongoDB.
So what do we mean by replication?
What we really mean is just having redundant copies of data like with disk drives. We do that all the time RAID inside a single machine. We’re talking about redundant copies across multiple machines.
A server, or a machine, or VM and of course each of these has some storage of their own. It could be internal and the arch attached or fiber attached, or whatever.
What we really want to do is basically?
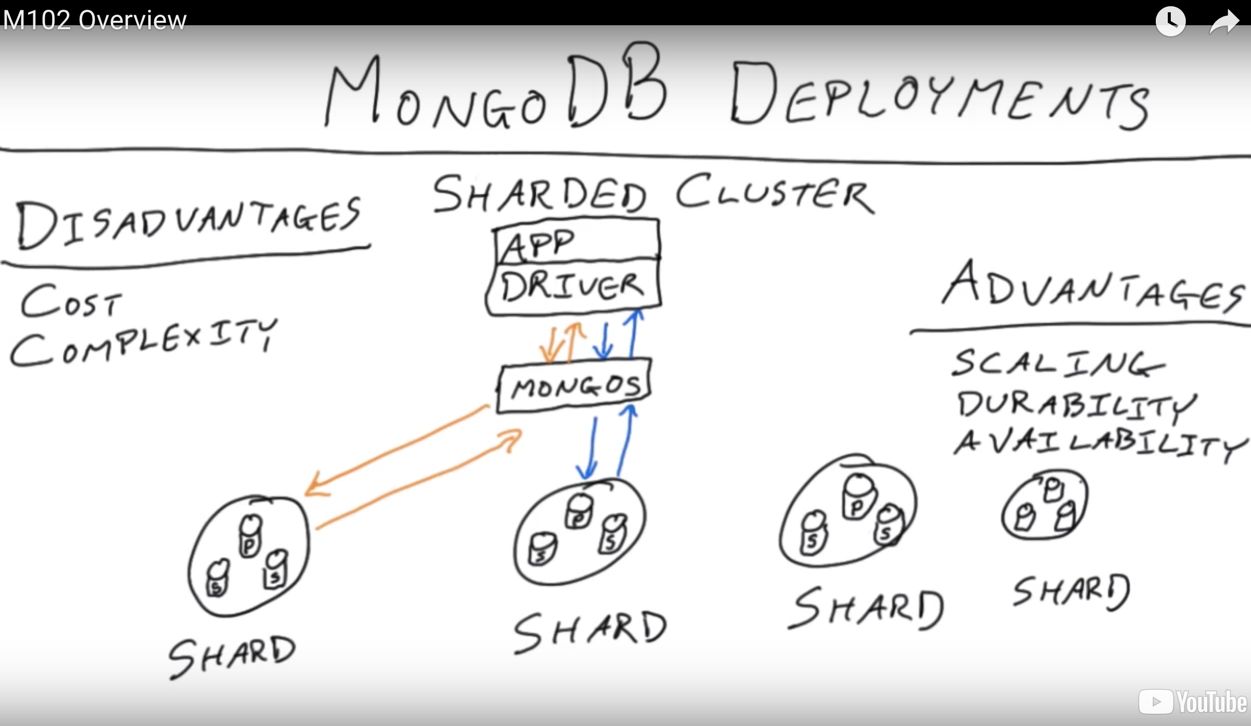
We’re going to have some document and what we’d like to do is get this document on multiple servers. So we’re really talking about multiple copies, redundant copies. We’re not trying to partition data for scale-out, you use the sharding feature in MongoDB for that of the same data.
If we loose a server, we’re still up, we have failover. It’s also just for data safety in terms of its durability and it’s both just having extra copies or backups if you will. And also “DR”, or disaster recovery, which I think maybe factors in both availability and safety of data.
There is another aspect to this which is, if we have copies in multiple places, we could potentially read from different places. We could read or query from here, or from here, or from here, and you could use that to get a little bit of scalability. You could also use that for geographic purposes– these servers don’t have to be in the same facility– and you could also use it if you have different workloads, then put them on different servers. - read preference
Quiz
Why do we use replica sets? Check all that apply.
High availability
Durability
Scaling in some situations
Disaster recovery
Asynchronous Replication
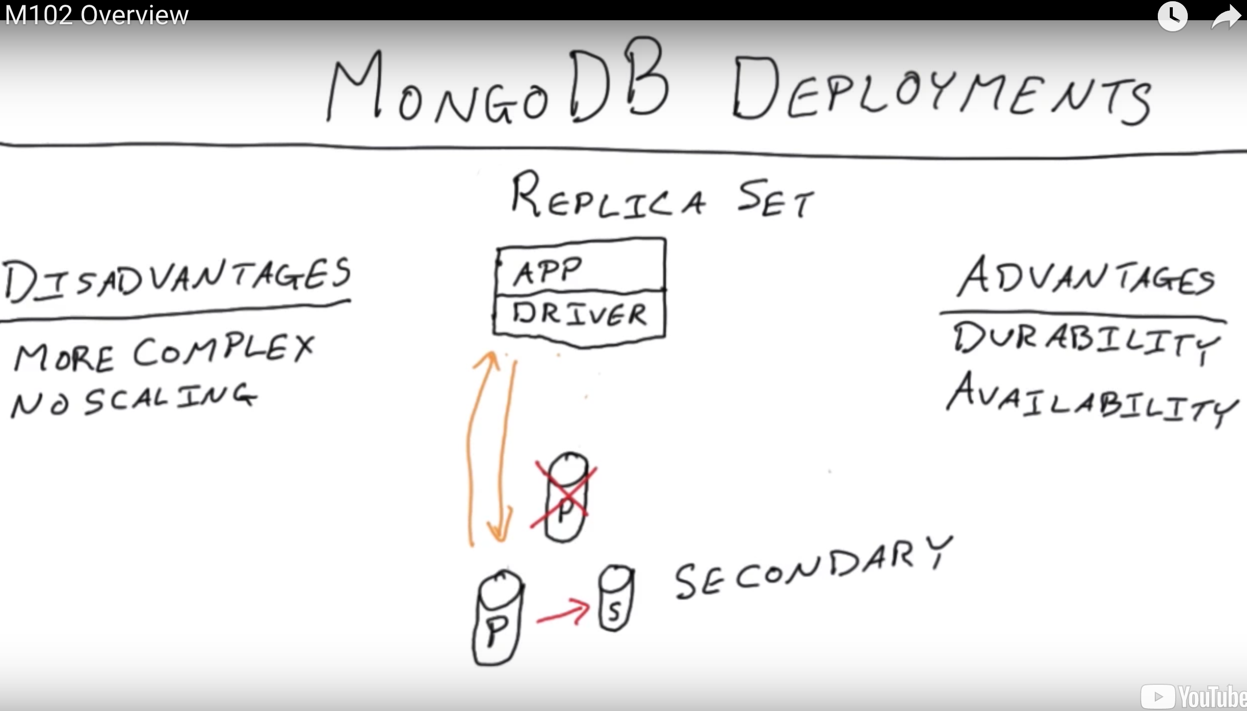
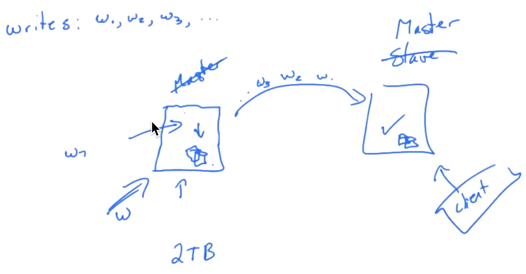
This is your master and you replicate data to a slave or secondary. We actually use the term primary in MongoDB so this is our slave database.
It’s common that this replication be asynchronous which means I have some clients here. Client does a write to this data by a database. The writes committed here and it’s going to take some time to get over the network over to primary and get processed and committed over slave.
In fact I can get an acknowledgment back here before that replication actually has occurred. Like in a lot of databases there may be options to do asynchronous or synchronous replication if you do synchronous replication in the database there would be some sort of probably like a two-phase commit here with some communication back and forth before this acknowledgement happens. So generally if you’re doing synchronous replication the machines tend to be side-by-side on a very low latency network connecting them. Thus I think the common case is to do asynchronous replication which can work over a more commodity type LAN or LAN environment.
In fact on wide area networks you have to do asynchronous because of this latency. If you will just do that the communication would be too high. You know if we want to do replication from continent to continent, the order of magnitude 100 milliseconds here just for a round-trip of one communication cycle, so things are going to be very slow. That is why MongoDB does asynchronous and requires stronger consistency.
Quiz
Which of the following are true about replication in MongoDB?
works on commodity hardware
supports a model of relication with a single primary and multiple secondaries
works across wide area networks
provides eventual consistency
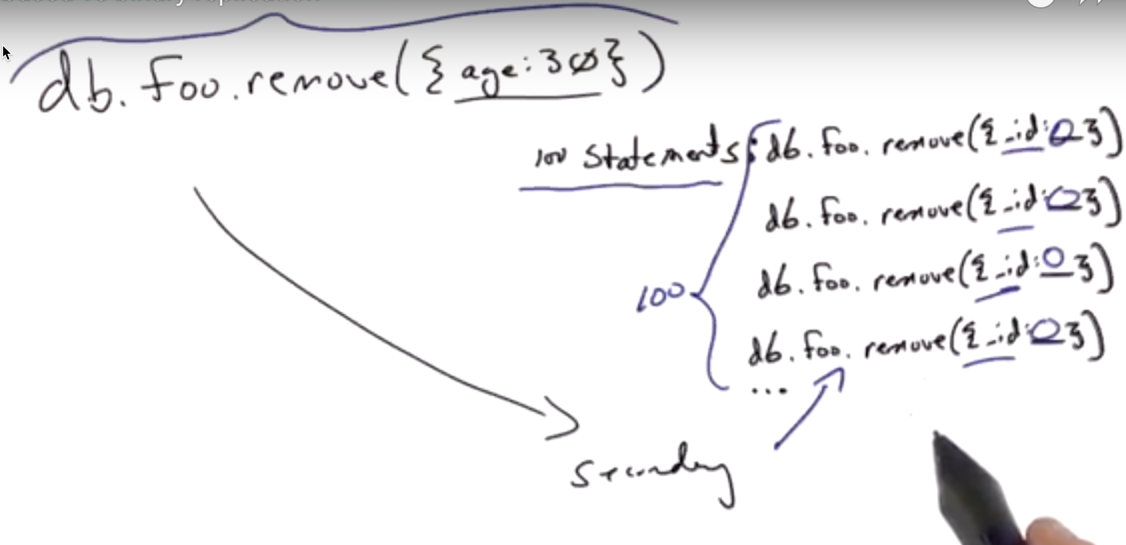
Statement-based vs. Binary Replication
Binary replication could be efficient, but it needs exact byte by byte of physical contents of data files in the secondary storage. Assume the diverse versions of mongodb on primary and secondary, there could be incompatible.
Statement-based way needs to be transformed as you see in the picture.
Mongodb uses statemtn-based way.
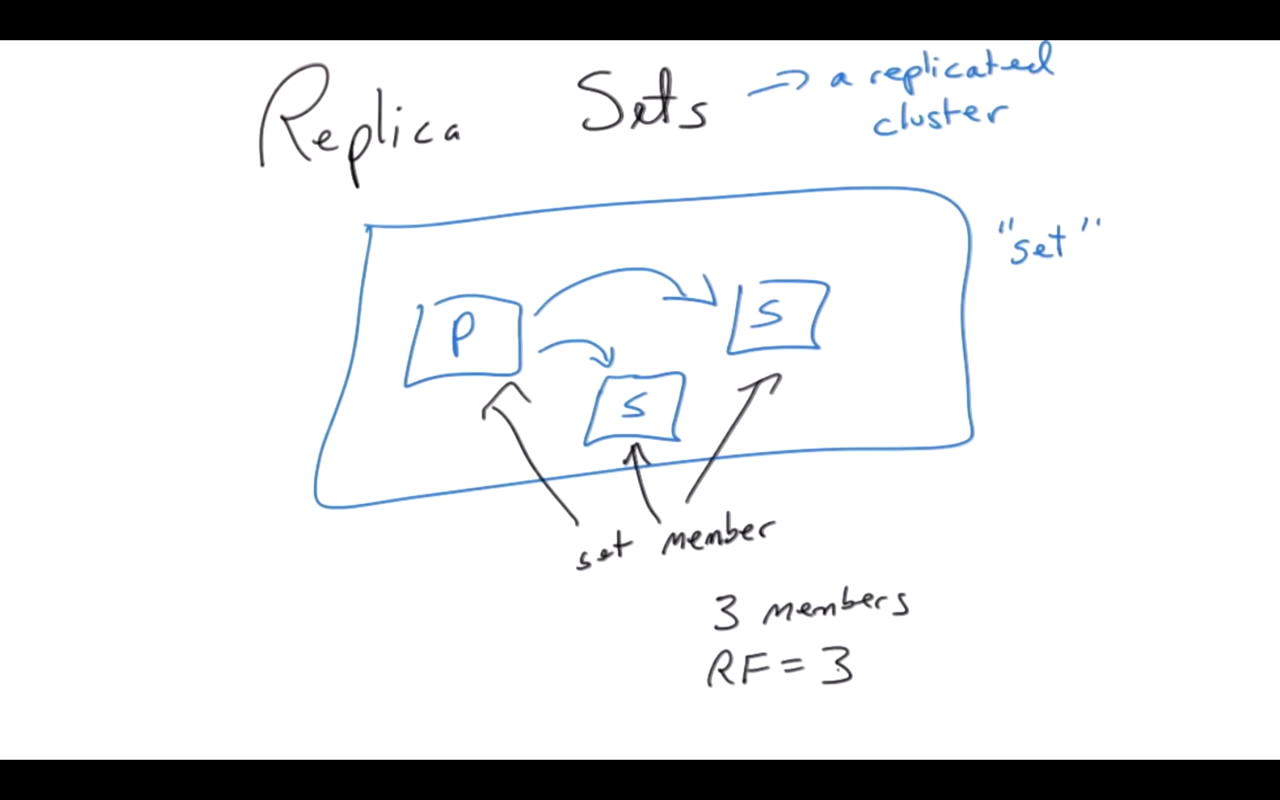
Replication Concepts
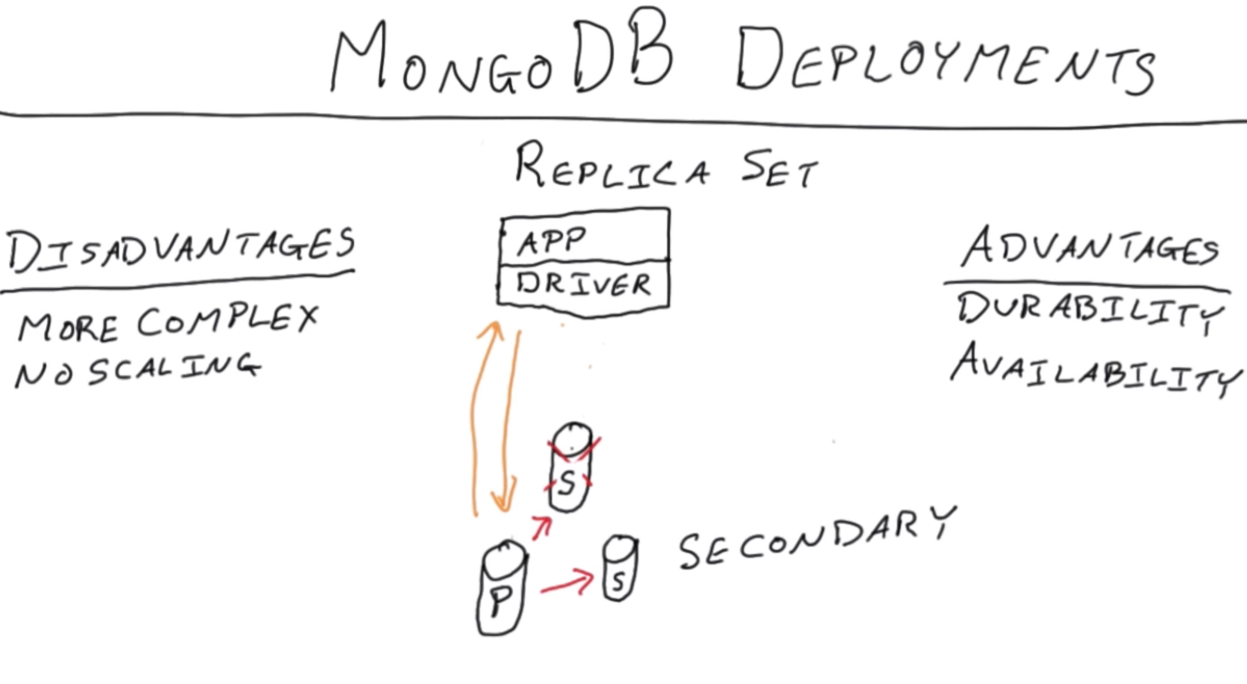
Replication Sets = a replicated cluster
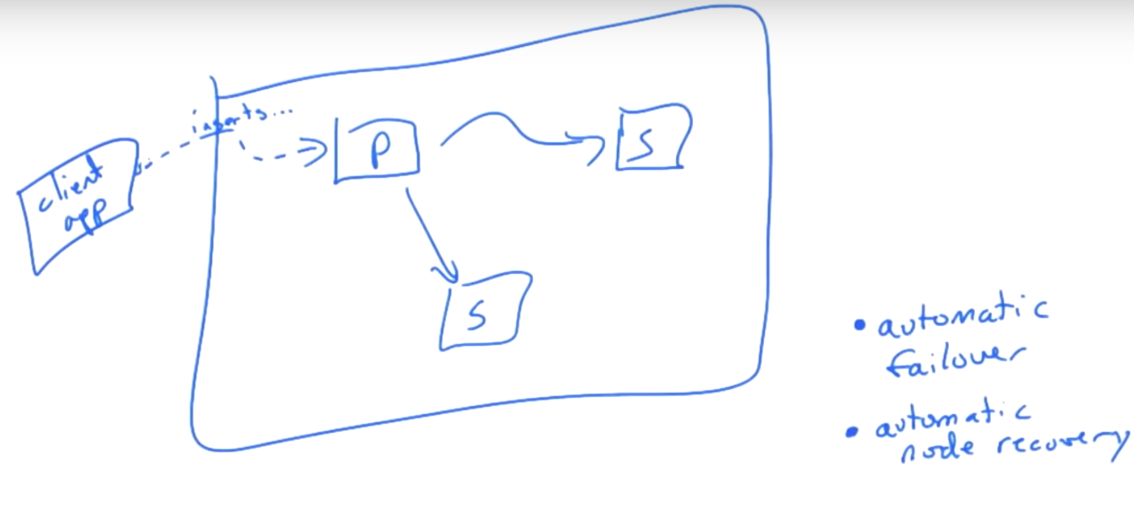
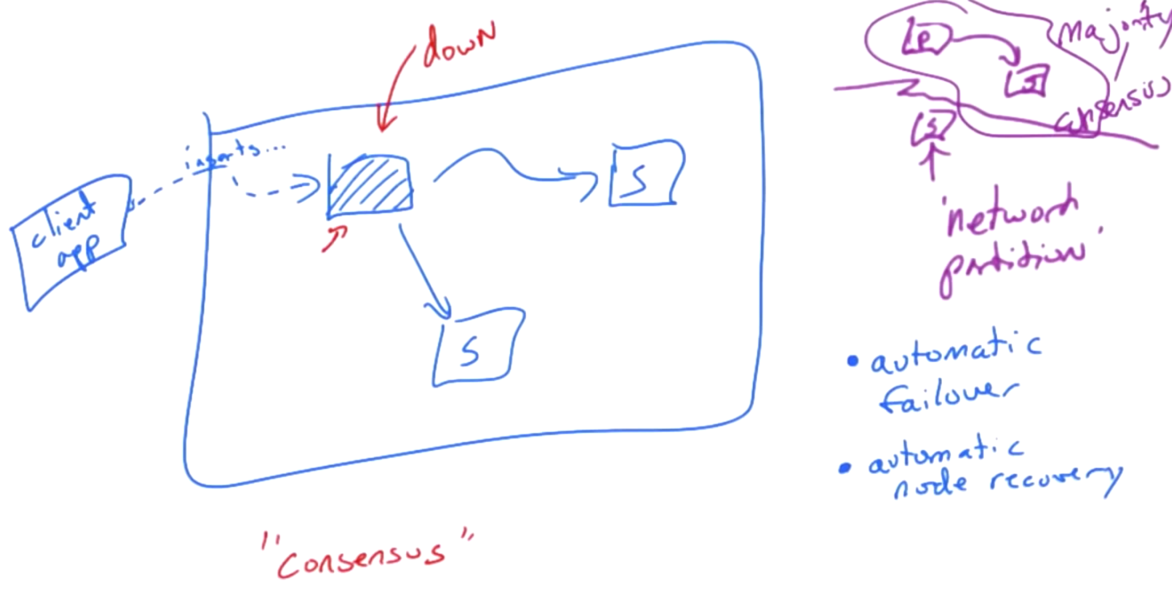
Automatic Failover
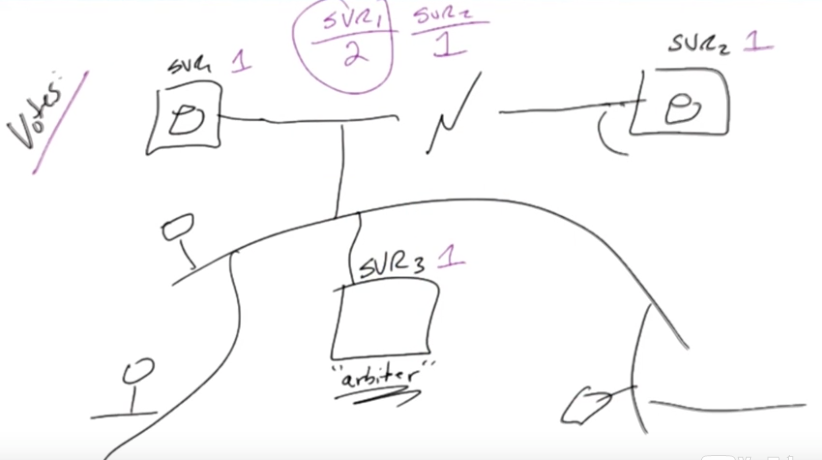
Assume there are three nodes. One is primary, the others are seccondary. Client app connects to primary, reads and writes data.
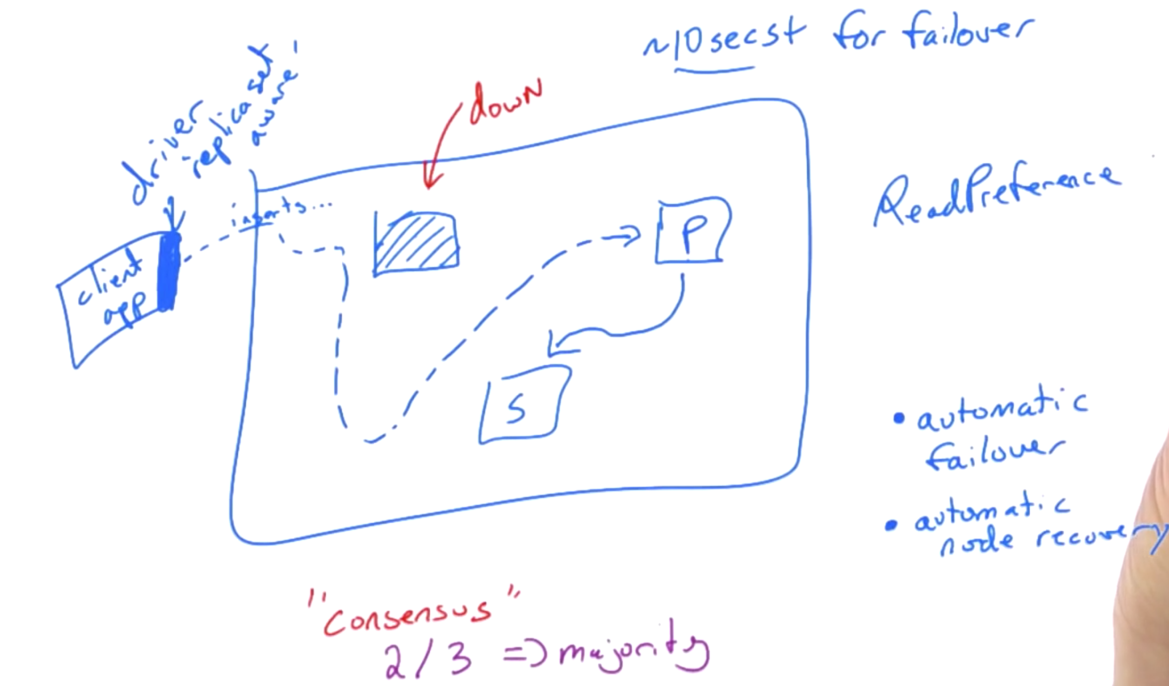
When primary is down, the rest of two secondary would go through ‘majority consensus(2/3 here)’. One of them may become the primary and continue the work. That’s automatic failover. This process may take some seconds.
There is read reference. It may choose one of the replica to read data, but writing is on primary.
Quiz
Imagine a replica set with 5 servers. What is the minimum number of servers (assume each server has 1 vote) to form a consensus?
3
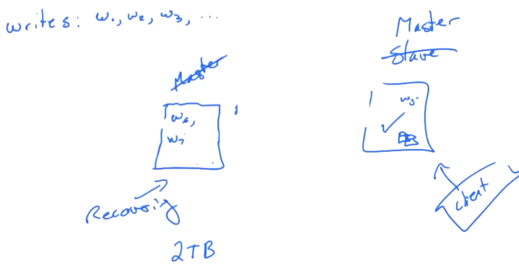
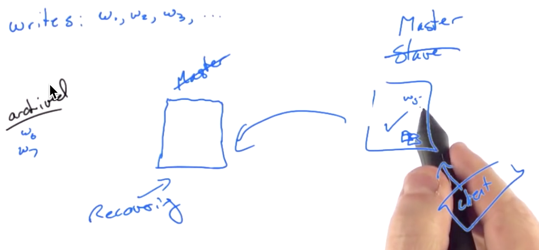
Recovery (continued as above)
That server recovers.
The lefthand side server is back.
Before lefthand side server was down, w1-w5 were all copied to righthand side server. So all the data is consistent. However, it committed w6 and w7 before it went down and the righthand side master server didn’t get those commits.
At the same time, there are some new write commits on righthand side server.
In that case, when lefthand side server gets on line again, the commits of w6 and w7 would be wiped out and achrived (rollback). Additionaly, those new commits on righthand side server would be copied to it. After that, the archived w6 and w7 will be got knowledgent of cluster-wide commit by a facility.
Quiz
Which of the following scenarios can trigger a rollback?
A secondary (that was previously a primary) contains write operations that are ahead of the current primary
Starting Replica Sets
how to make a replica set?
ports : –port
dbpath : –dbpath
replica set name : –replSet
Example - create replica sets with 3 nodes
create a folder named abc for replica name and three folders for three nodes
// continued above ➜ workspace08 hostname Allens-Mac.local ➜ workspace08 ping Allens-Mac.local PING allens-mac.local (192.168.1.110): 56 data bytes 64 bytes from 192.168.1.110: icmp_seq=0 ttl=64 time=0.066 ms 64 bytes from 192.168.1.110: icmp_seq=1 ttl=64 time=0.104 ms 64 bytes from 192.168.1.110: icmp_seq=2 ttl=64 time=0.078 ms 64 bytes from 192.168.1.110: icmp_seq=3 ttl=64 time=0.081 ms 64 bytes from 192.168.1.110: icmp_seq=4 ttl=64 time=0.082 ms ^C --- allens-mac.local ping statistics --- 5 packets transmitted, 5 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 0.066/0.082/0.104/0.012 ms ➜ workspace08 cat /etc/hosts ## # Host Database # # localhost is used to configure the loopback interface # when the system is booting. Do not change this entry. ## 127.0.0.1 localhost 255.255.255.255 broadcasthost ::1 localhost 127.0.0.1 AcronisDriveSearchPlugin 127.0.0.1 windows10.microdone.cn ➜ workspace08
➜ workspace08 mongo --port 27001 MongoDB shell version: 3.2.18 connecting to: 127.0.0.1:27001/test MongoDB Enterprise > MongoDB Enterprise > cfg = { _id : "abc", members : [ { _id:0, host:"Allens-Mac.local:27001" }, { _id:1, host:"Allens-Mac.local:27002" }, { _id:2, host:"Allens-Mac.local:27003" } ] } { "_id" : "abc", "members" : [ { "_id" : 0, "host" : "Allens-Mac.local:27001" }, { "_id" : 1, "host" : "Allens-Mac.local:27002" }, { "_id" : 2, "host" : "Allens-Mac.local:27003" } ] } MongoDB Enterprise > rs.help() rs.status() { replSetGetStatus : 1 } checks repl set status rs.initiate() { replSetInitiate : null } initiates set with default settings rs.initiate(cfg) { replSetInitiate : cfg } initiates set with configuration cfg rs.conf() get the current configuration object from local.system.replset rs.reconfig(cfg) updates the configuration of a running replica set with cfg (disconnects) rs.add(hostportstr) add a new member to the set with default attributes (disconnects) rs.add(membercfgobj) add a new member to the set with extra attributes (disconnects) rs.addArb(hostportstr) add a new member which is arbiterOnly:true (disconnects) rs.stepDown([stepdownSecs, catchUpSecs]) step down as primary (disconnects) rs.syncFrom(hostportstr) make a secondary sync from the given member rs.freeze(secs) make a node ineligible to become primary for the time specified rs.remove(hostportstr) remove a host from the replica set (disconnects) rs.slaveOk() allow queries on secondary nodes
rs.printReplicationInfo() check oplog size and time range rs.printSlaveReplicationInfo() check replica set members and replication lag db.isMaster() check who is primary
reconfiguration helpers disconnect from the database so the shell will display an error, even if the command succeeds.
1 2 3 4 5 6
MongoDB Enterprise > // rs.initiate(cfg) MongoDB Enterprise > rs.initiate(cfg) { "ok" : 1 } MongoDB Enterprise abc:OTHER> MongoDB Enterprise abc:OTHER> // after a while, replica set becomes ready, so PRIMARY MongoDB Enterprise abc:PRIMARY>
# primary tab (port 27002) (the node that becomes primary after the original primary node was killed) MongoDB Enterprise abc:PRIMARY> db.foo.insert({_id: "post failover"}) WriteResult({ "nInserted" : 1 })
# After the above command, # if you check log.1 about the original primary node, # you can find the ***** SERVER RESTARTED ***** 2018-02-24T21:46:37.488+0800 I STORAGE [signalProcessingThread] shutdown: final commit... 2018-02-24T21:46:37.497+0800 I JOURNAL [signalProcessingThread] journalCleanup... 2018-02-24T21:46:37.497+0800 I JOURNAL [signalProcessingThread] removeJournalFiles 2018-02-24T21:46:37.500+0800 I JOURNAL [signalProcessingThread] Terminating durability thread ... 2018-02-24T21:46:37.601+0800 I JOURNAL [journal writer] Journal writer thread stopped 2018-02-24T21:46:37.604+0800 I JOURNAL [durability] Durability thread stopped 2018-02-24T21:46:37.605+0800 I STORAGE [signalProcessingThread] shutdown: closing all files... 2018-02-24T21:46:37.610+0800 I STORAGE [signalProcessingThread] closeAllFiles() finished 2018-02-24T21:46:37.611+0800 I STORAGE [signalProcessingThread] shutdown: removing fs lock... 2018-02-24T21:46:37.611+0800 I CONTROL [signalProcessingThread] dbexit: rc: 0 2018-02-24T22:01:44.606+0800 I CONTROL [main] ***** SERVER RESTARTED ***** 2018-02-24T22:01:44.643+0800 I CONTROL [initandlisten] MongoDB starting : pid=9687 port=27001 dbpath=/Users/allen/Documents/Code/workspace08/data/db-MMAPv1-cluster/abc/1 64-bit host=Allens-Mac.local 2018-02-24T22:01:44.643+0800 I CONTROL [initandlisten] db version v3.2.18 2018-02-24T22:01:44.644+0800 I CONTROL [initandlisten] git version: 4c1bae566c0c00f996a2feb16febf84936ecaf6f 2018-02-24T22:01:44.644+0800 I CONTROL [initandlisten] OpenSSL version: OpenSSL 0.9.8zh 14 Jan 2016 2018-02-24T22:01:44.644+0800 I CONTROL [initandlisten] allocator: system 2018-02-24T22:01:44.645+0800 I CONTROL [initandlisten] modules: enterprise 2018-02-24T22:01:44.645+0800 I CONTROL [initandlisten] build environment: 2018-02-24T22:01:44.645+0800 I CONTROL [initandlisten] distarch: x86_64 2018-02-24T22:01:44.645+0800 I CONTROL [initandlisten] target_arch: x86_64 2018-02-24T22:01:44.646+0800 I CONTROL [initandlisten] options: { net: { port: 27001 }, processManagement: { fork: true }, replication: { oplogSizeMB: 50, replSet: "abc" }, storage: { dbPath: "/Users/allen/Documents/Code/workspace08/data/db-MMAPv1-cluster/abc/1", engine: "mmapv1", mmapv1: { smallFiles: true } }, systemLog: { destination: "file", logAppend: true, path: "/Users/allen/Documents/Code/workspace08/data/db-MMAPv1-cluster/abc/log.1" } }
1 2 3
# the new primary node's tab (port 27002) MongoDB Enterprise abc:PRIMARY> MongoDB Enterprise abc:PRIMARY>
Quiz
When a primary goes down and then is brought back online, it will always resume primary status:
False
Read Preference
passive to read as we do in the above a.k.a. “slaveOK” rs.slaveOk()
proactive to read based on these factors -> eventual consistency
geography
separate a workload (analytics server)
coporate load
availability
Quiz
What are good reasons to read from a secondary?
Geographic reads(latency)
Separate a workload (analytics/reporting)
High availability (during a failover)
Read Preference Options
primary (default, keep the load off the secondary, all reads hit primary)
primary preferred (try to talk to primary, but if you cannot talk to primary, you can read the secondary)
secondary (keep the load off the primary, all reads hit secondaries)
secondary preferred (read secondary first, but if you cannot talk to secondary, talk to primary)
nearest (find the nearest node to read)
strategies
when in doubt, primary preferred
when remote use nearest
use secondary for certain reporting workloads
even read loads, consider nearest
Quiz
For reads which must be consistent, which read preference(s) is used?
Primary
Homework 4.1
In this chapter’s homework we will create a replica set and add some data to it.
Download the replication.js handout.
We will create a three member replica set. Pick a root working directory to work in. Go to that directory in a console window.
Given we will have three members in the set, and three mongod processes, create three data directories:
1 2 3
mkdir 1 mkdir 2 mkdir 3
We will now start a single mongod as a standalone server. Given that we will have three mongod processes on our single test server, we will explicitly specify the port numbers (this wouldn’t be necessary if we had three real machines or three virtual machines). We’ll also use the –smallfiles parameter and –oplogSize so the files are small given we have a lot of server processes running on our test PC.
1 2
# starting as a standalone server for problem 1: mongod --dbpath 1 --port 27001 --smallfiles --oplogSize 50
Note: for all mongod startups in the homework this chapter, you can optionally use –logPath, –logappend, and –fork. Or, since this is just an exercise on a local PC, you could simply have a separate terminal window for all and forgo those settings. Run “mongod –help” for more info on those.
In a separate terminal window (cmd.exe on Windows), run the mongo shell with the replication.js file:
1
mongo --port 27001 --shell replication.js
Then run in the shell:
1
homework.init()
This will load a small amount of test data into the database.
Now run:
1
homework.a()
and enter the result. This will simply confirm all the above happened ok.
Enter answer here: 5001
set up a standalone instance, then invoke the methods in replication.js as required
Now convert the mongod instance (the one in the problem 4.1 above, which uses “–dbpath 1”) to a single server replica set. To do this, you’ll need to stop the mongod (NOT the mongo shell instance) and restart it with “–replSet” on its command line. Give the set any name you like.
Then go to the mongo shell. Once there, run
rs.initiate()
Note: if you do not specify a configuration, the mongod will pick one based on your computer’s hostname.
When you first ran homework.init(), we loaded some data into the mongod. You should see it in the replication database. You can confirm with:
use replication db.foo.find()
Once done with that, run
homework.b()
in the mongo shell and enter that result below.
Enter answer here: 5002
set up a replica set instance, then invoke the methods in replication.js as required
# kill the previous instance at first, then do the below. ➜ workspace08 mongod --port 27001 --replSet "homework4" --dbpath /Users/allen/Documents/Code/workspace08/data/db-MMAPv1-cluster/homework/1 --logpath /Users/allen/Documents/Code/workspace08/data/db-MMAPv1-cluster/homework/log.1 --logappend --oplogSize 50 --smallfiles --fork --storageEngine=mmapv1 about to fork child process, waiting until server is ready for connections. forked process: 11054 child process started successfully, parent exiting ➜ workspace08 mongo --port 27001 MongoDB shell version: 3.2.18 connecting to: 127.0.0.1:27001/test MongoDB Enterprise > rs.initiate() { "info2" : "no configuration specified. Using a default configuration for the set", "me" : "Allens-Mac.local:27001", "ok" : 1 } MongoDB Enterprise homework4:OTHER> ^C bye ➜ workspace08 mongo --port 27001 --shell MongoDB-DBA/Chapter04/replication.js MongoDB shell version: 3.2.18 connecting to: 127.0.0.1:27001/test type"help"forhelp MongoDB Enterprise homework4:PRIMARY> homework.init() ok MongoDB Enterprise homework4:PRIMARY> use replication switched to db replication MongoDB Enterprise homework4:PRIMARY> db.foo.find() { "_id" : ObjectId("5a91833dcef5591a56f28436"), "x" : 0, "y" : 0.19671888543734684 } { "_id" : ObjectId("5a91833dcef5591a56f28437"), "x" : 1, "y" : 0.7696225680223695 } { "_id" : ObjectId("5a91833dcef5591a56f28438"), "x" : 2, "y" : 0.35312289985279655 } { "_id" : ObjectId("5a91833dcef5591a56f28439"), "x" : 3, "y" : 0.6357476779463604 } { "_id" : ObjectId("5a91833dcef5591a56f2843a"), "x" : 4, "y" : 0.8470530410580647 } { "_id" : ObjectId("5a91833dcef5591a56f2843b"), "x" : 5, "y" : 0.9860132768933882 } { "_id" : ObjectId("5a91833dcef5591a56f2843c"), "x" : 6, "y" : 0.27720445773819635 } { "_id" : ObjectId("5a91833dcef5591a56f2843d"), "x" : 7, "y" : 0.71086710411818 } { "_id" : ObjectId("5a91833dcef5591a56f2843e"), "x" : 8, "y" : 0.2544181675963868 } { "_id" : ObjectId("5a91833dcef5591a56f2843f"), "x" : 9, "y" : 0.32591085230580874 } { "_id" : ObjectId("5a91833dcef5591a56f28440"), "x" : 10, "y" : 0.26594646048303094 } { "_id" : ObjectId("5a91833dcef5591a56f28441"), "x" : 11, "y" : 0.744608674773003 } { "_id" : ObjectId("5a91833dcef5591a56f28442"), "x" : 12, "y" : 0.05895571157658808 } { "_id" : ObjectId("5a91833dcef5591a56f28443"), "x" : 13, "y" : 0.41340713465842494 } { "_id" : ObjectId("5a91833dcef5591a56f28444"), "x" : 14, "y" : 0.1941464406594522 } { "_id" : ObjectId("5a91833dcef5591a56f28445"), "x" : 15, "y" : 0.9021870853734707 } { "_id" : ObjectId("5a91833dcef5591a56f28446"), "x" : 16, "y" : 0.9027339339897847 } { "_id" : ObjectId("5a91833dcef5591a56f28447"), "x" : 17, "y" : 0.5447723820562963 } { "_id" : ObjectId("5a91833dcef5591a56f28448"), "x" : 18, "y" : 0.6886308741514784 } { "_id" : ObjectId("5a91833dcef5591a56f28449"), "x" : 19, "y" : 0.1367301905393813 } Type "it"for more MongoDB Enterprise homework4:PRIMARY> homework.b() 5002 MongoDB Enterprise homework4:PRIMARY>
Homework 4.3
Now add two more members to the set. Use the 2/ and 3/ directories we created in homework 4.1. Run those two mongod’s on ports 27002 and 27003 respectively (the exact numbers could be different).
Remember to use the same replica set name as you used for the first member.
You will need to add these two new members to your replica set, which will initially have only one member. In the shell running on the first member, you can see your replica set status with
rs.status()
Initially it will have just that first member. Connecting to the other members will involve using
rs.add()
For example,
rs.add("localhost:27002")
Note that ‘localhost’ almost certainly won’t work for you unless you have already set it as ‘localhost’ in the previous problem. If not, try using the name in the “members.name” field in the document you get by calling rs.status(), but remember to use the correct port!.
You’ll know it’s added when you see an { "ok" : 1 } document.
Once a secondary has spun up, you can connect to it with a new mongo shell instance. Use
rs.slaveOk()
to let the shell know you’re OK with (potentially) stale data, and run some queries. You can also insert data on your primary and then read it out on your secondary.
Once you have two secondary servers, both of which have sync’d with the primary and are caught up, run (on your primary):
homework.c()
and enter the result below.
Enter answer here: 5
solution01
s0
1 2 3 4 5 6 7 8 9
➜ workspace08 mongod --port 27002 --replSet "homework4" --dbpath /Users/allen/Documents/Code/workspace08/data/db-MMAPv1-cluster/homework/2 --logpath /Users/allen/Documents/Code/workspace08/data/db-MMAPv1-cluster/homework/log.2 --logappend --oplogSize 50 --smallfiles --fork --storageEngine=mmapv1 about to fork child process, waiting until server is ready for connections. forked process: 11139 child process started successfully, parent exiting ➜ workspace08 mongod --port 27003 --replSet "homework4" --dbpath /Users/allen/Documents/Code/workspace08/data/db-MMAPv1-cluster/homework/3 --logpath /Users/allen/Documents/Code/workspace08/data/db-MMAPv1-cluster/homework/log.3 --logappend --oplogSize 50 --smallfiles --fork --storageEngine=mmapv1 about to fork child process, waiting until server is ready for connections. forked process: 11147 child process started successfully, parent exiting ➜ workspace08
# port 27002 MongoDB Enterprise > rs.add("Allens-Mac.local:27002") { "ok" : 0, "errmsg" : "replSetReconfig should only be run on PRIMARY, but my state is SECONDARY; use the \"force\" argument to override", "code" : 10107 } MongoDB Enterprise homework4:SECONDARY>
1 2 3 4 5 6 7 8
# port 27003 MongoDB Enterprise homework4:SECONDARY> rs.add("Allens-Mac.local:27003") { "ok" : 0, "errmsg" : "replSetReconfig should only be run on PRIMARY, but my state is SECONDARY; use the \"force\" argument to override", "code" : 10107 } MongoDB Enterprise homework4:SECONDARY>
# port 27002's tab ➜ workspace08 mongod --port 27002 --replSet "homework4" --dbpath /Users/allen/Documents/Code/workspace08/data/db-MMAPv1-cluster/homework/2 --logpath /Users/allen/Documents/Code/workspace08/data/db-MMAPv1-cluster/homework/log.2 --logappend --oplogSize 50 --smallfiles --fork --storageEngine=mmapv1 about to fork child process, waiting until server is ready for connections. forked process: 11763 child process started successfully, parent exiting
1 2 3 4 5 6
# port 27003's tab ➜ workspace08 mongod --port 27003 --replSet "homework4" --dbpath /Users/allen/Documents/Code/workspace08/data/db-MMAPv1-cluster/homework/3 --logpath /Users/allen/Documents/Code/workspace08/data/db-MMAPv1-cluster/homework/log.3 --logappend --oplogSize 50 --smallfiles --fork --storageEngine=mmapv1 about to fork child process, waiting until server is ready for connections. forked process: 11773 child process started successfully, parent exiting
# port 27003's tab ➜ workspace08 mongo --port 27003 --shell MongoDB-DBA/Chapter04/replication.js MongoDB shell version: 3.2.18 connecting to: 127.0.0.1:27003/test type"help"forhelp homework4:SECONDARY>
after solution1 or solution2
1 2 3 4 5
# port 27002 or port 27003 MongoDB Enterprise homework4:SECONDARY> rs.slaveOk() MongoDB Enterprise homework4:SECONDARY> homework.c() 5 MongoDB Enterprise homework4:SECONDARY>
Homework 4.4
We will now remove the first member (@ port 27001) from the set.
As a first step to doing this we will shut it down. (Given the rest of the set can maintain a majority, we can still do a majority reconfiguration if it is down.)
We could simply terminate its mongod process, but if we use the replSetStepDown command, the failover may be faster. That is a good practice, though not essential. Connect to member 1 (port 27001) in the shell and run:
rs.stepDown()
Then cleanly terminate the mongod process for member 1.
Next, go to the new primary of the set. You will probably need to connect with the mongo shell, which you’ll want to run with ‘–shell replication.js’ since we’ll be getting the homework solution from there. Once you are connected, run rs.status() to check that things are as you expect. Then reconfigure to remove member 1.
Tip: You can either use rs.reconfig() with your new configuration that does not contain the first member, or rs.remove(), specifying the host:port of the server you wish to remove as a string for the input.
When done, run:
> homework.d()
and enter the result.
Trouble-Shooting Tips
Make sure that your replica set has _id’s 0, 1, and 2 set. If you didn’t use a custom config, you should be fine, but this is an issue that has come up when using custom configurations.
If you ran the shell without replication.js on the command line, restart the shell with it. Enter answer here:
s1
1 2 3 4 5 6 7 8 9 10 11
# port 27001 MongoDB Enterprise homework4:PRIMARY> rs.stepDown() 2018-02-25T00:52:19.647+0800 E QUERY [thread1] Error: error doing query: failed: network error while attempting to run command'replSetStepDown' on host '127.0.0.1:27001' : DB.prototype.runCommand@src/mongo/shell/db.js:135:1 DB.prototype.adminCommand@src/mongo/shell/db.js:153:16 rs.stepDown@src/mongo/shell/utils.js:1202:12 @(shell):1:1
2018-02-25T00:52:19.650+0800 I NETWORK [thread1] trying reconnect to 127.0.0.1:27001 (127.0.0.1) failed 2018-02-25T00:52:19.652+0800 I NETWORK [thread1] reconnect 127.0.0.1:27001 (127.0.0.1) ok MongoDB Enterprise homework4:SECONDARY>
# port 27002 MongoDB Enterprise homework4:SECONDARY>
Homework 4.5
Note our replica set now has an even number of members, and that is not a best practice. However, to keep the homework from getting too long we’ll leave it at that for now, and instead do one more exercise below involving the oplog.
To get the right answer on this problem, you must perform the homework questions in order. Otherwise, your oplog may look different than we expect.
Go to the secondary in the replica set. The shell should say SECONDARY at the prompt if you’ve done everything correctly.
Switch to the local database and then look at the oplog:
db.oplog.rs.find()
If you get a blank result, you are not on the right database.
Note: as the local database doesn’t replicate, it will let you query it without entering “rs.slaveOk()” first.
Next look at the stats on the oplog to get a feel for its size:
db.oplog.rs.stats()
What result does this expression give when evaluated?
Note that if you inserted many documents (more than around 500,000), your oplog will roll over and eliminate the document that you need. If this happens, you’ll need to repeat the previous problems with a set of clean directories in order to find the answer to this question.
When a server is down, you can do reconfiguration with some options.
Quiz
Which of the following statements are true about reconfiguring a replica set?
Servers can be either removed from the replica set, or added
If a member of the replica set is not available, the replica set can still be reconfigured
Arbiters
Arbiters are mongod instances that are part of a replica set but do not hold data. Arbiters participate in elections in order to break ties. If a replica set has an even number of members, add an arbiter.
Arbiters are voters as well, as you see. It can help the voting.
The number of seconds “behind” the primary that this replica set member should “lag”.
Use this option to create delayed members. Delayed members maintain a copy of the data that reflects the state of the data at some time in the past. This can help recovery data in case incorrect data manipulations.
Lecture Notes
To configure a delayed secondary member, set its priority value to 0, its hidden value to true, and its slaveDelay value to the number of seconds to delay.
Here is the link to the documentation.
Also, a delayed secondary has other disadvantages: since it can’t become primary, it’s less useful for ensuring high availability than a standard secondary.
If you would like to be able to undo a human error on your replica set, you also have other options available:
You can replay your oplog up to the error. You can use MMS Backup.
Quiz
In which of the following scenarios does it make sense to use slave delay?
Prevent against a new client application release bug
During development when using experimental queries
Voting Options
Don’t use votes option.
Lecture Notes
As of MongoDB 3.0, a replica set member can only have 0 or 1 vote.
In this video, Dwight mentions that changing votes for members of a replica set would not be a best practice, but there is one exception.
Mongodb allows seven voting members in a replica set, so if your replica set has more than seven members, you will need to assign any further members a vote of zero.
Having more than seven members in a replica set is fairly unusual, so this issue would not come up in most vanilla MongoDB deployments.
Quiz
Generally, is it typical for servers to have different vote counts?
No
Applied Reconfiguration
If you set hidden true, priority 0, and slaveDelay 3600 * 8 on secondary on port 27003, this node will not be list in ‘host’ of rs.isMaster(). Let’s do the experiements.
# secondary: port 27002 MongoDB Enterprise abc:SECONDARY>
1 2 3 4 5 6 7 8 9 10 11 12
# secondary: port 27003 MongoDB Enterprise abc:SECONDARY> 2018-02-25T16:54:01.121+0800 I NETWORK [thread1] trying reconnect to 127.0.0.1:27003 (127.0.0.1) failed 2018-02-25T16:54:01.121+0800 W NETWORK [thread1] Failed to connect to 127.0.0.1:27003, in(checking socket for error after poll), reason: errno:61 Connection refused 2018-02-25T16:54:01.121+0800 I NETWORK [thread1] reconnect 127.0.0.1:27003 (127.0.0.1) failed failed MongoDB Enterprise > ^C bye ➜ ~ ➜ ~ mongo --port 27003 MongoDB shell version: 3.2.18 connecting to: 127.0.0.1:27003/test MongoDB Enterprise abc:SECONDARY>
Lecture Notes
At the 1:00 mark or so, there is a mistake.
slaveDelay: true will be thrown out on reconfiguration. Instead, use an integer for the number of seconds delayed, such as:
slaveDelay: 120
in order to give yourself 2 minutes to recover from user error.
One thing to keep in mind, these days, is that you can do a snapshot of your data periodically, and use the oplog for a point-in-time restore (there’s a hands on version of this problem in M123), so slaveDelay is perhaps not as useful as it once was.
Write Concern Principles
In this section, we are going to talk about this concept of a cluster wide commit, i.e., a replica set wide, cluster wide commit for that and what we call write concern in the drivers which is based on getlasterror which is a helper command we’ve used serveral times so far. Let’s go over this.
In previous seciton, you may recall we talked about replica sets - beyond doing just basic replication. The things we’re getting from them are automactic failover(失效备援(为系统备援能力的一种,当系统中其中一项设备失效而无法运作时,另一项设备即可自动接手原失效系统所执行的工作) when a node fails and automatic recovery when that node comes back. So when the node comes back and recovers, there can be a rollback of some operations whcih never made it out of that node to the other ones. They may not have made it out before it crashed because the replication is asynchronous. So those are archived, could be recovered, but the question on my mind is how do we know when something has made itfar enough around that we’re never going to lose it, and how many services does it have to get to before the rollback becomes impossible. It sounds like if it’s on one server, it can be rolled back. Does it have to be on all of them to be guranteed durable forever, or a subset of them. And the answer is that if it’s on a majority of the servers in the set, that implies it’s committed and by committed, durable, in a cluster wide fashion, even with failovers and recoveries of nodes that have gone down. And that is the concept with cluster wide commits and replica sets.
Imagine you’re using a 5-server replica set and you have critical inserts which you do not want the potential for a rollback to happen. You also have to consider that secondaries may be taken down from to time for maintenance, leaving you with a potential 4-server replica set. Which write concern is best suited for these critical inserts?
You can see that directories A and C have WiredTiger data files, while directory B has MMAPv1 data files, so “A” and “C” are the correct choices.
Homework 5.1
Set up a replica set that includes an arbiter.
To demonstrate that you have done this, what is the value in the “state” field for the arbiter when you run rs.status()?
Answer: 7
Homework 5.2
You have just been hired at a new company with an existing MongoDB deployment. They are running a single replica set with two members. When you ask why, they explain that this ensures that the data will be durable in the face of the failure of either server. They also explain that should they use a readPreference of “primaryPreferred”, that the application can read from the one remaining server during server maintenance.
You are concerned about two things, however. First, a server is brought down for maintenance once a month. When this is done, the replica set primary steps down, and the set cannot accept writes. You would like to ensure availability of writes during server maintenance.
Second, you also want to ensure that all writes can be replicated during server maintenance.
Which of the following options will allow you to ensure that a primary is available during server maintenance, and that any writes it receives will replicate during this time?
Add two data bearing members plus one arbiter.
or
Add another data bearing node.
Homework 5.3
You would like to create a replica set that is robust to data center failure.
You only have two data centers available. Which arrangement(s) of servers will allow you to be stay up (as in, still able to elect a primary) in the event of a failure of either data center (but not both at once)? Check all that apply.
All 3 servers in data center 1.
2 servers in data center 1, one server in data center 2.
None of the above.
Homework 5.4
Consider the following scenario: You have a two member replica set, a primary, and a secondary.
The data center with the primary goes down, and is expected to remain down for the foreseeable future. Your secondary is now the only copy of your data, and it is not accepting writes. You want to reconfigure your replica set config to exclude the primary, and allow your secondary to be elected, but you run into trouble. Find out the optional parameter that you’ll need, and input it into the box below for your rs.reconfig(new_cfg, OPTIONAL PARAMETER).
Your answer should be of the form { key : value } (including brackets). Do not include the rs.reconfig portion of the query, just the options document.
Answer: { “force” : true }
This operation forces the secondary to use the new configuration. The configuration is then propagated to all the surviving members listed in the members array. The replica set then elects a new primary.